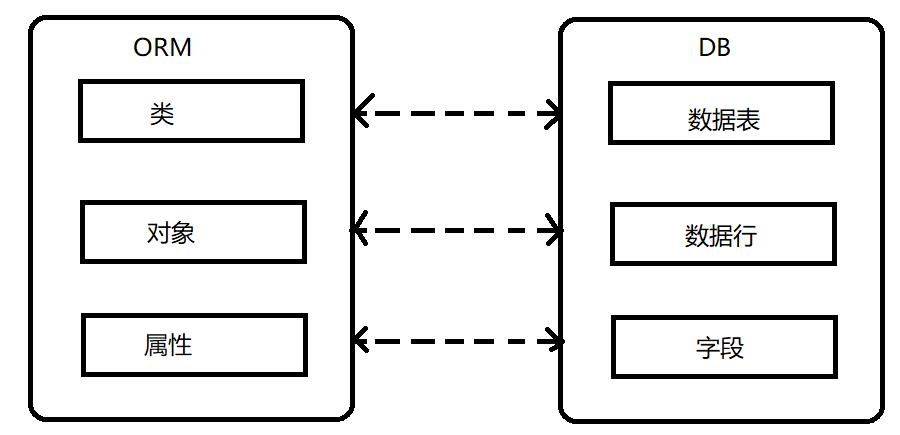
这篇继续学习Beego框架,主要学习一下Beego自带的的ORM 框架,并学习其他的ORM框架如XORM
Beego ORM
Demo
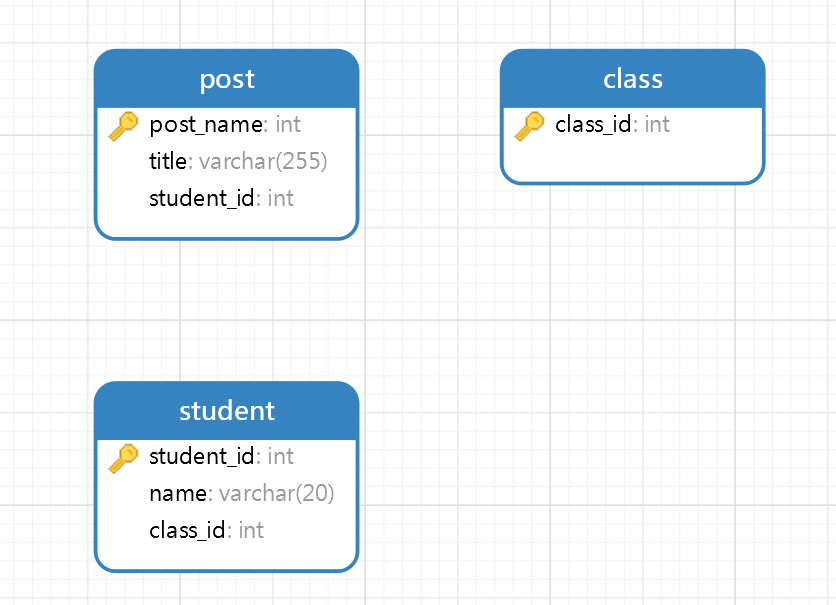
这部分直接上代码。ORM其实就是持久化技术,即把对象持久化到数据库中,比如spring的JPA等,Beego自己也有自己的ORM框架。按照常例,我们在model中去定义我们的数据结构就可以了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 package modelsimport "github.com/beego/beego/v2/client/orm" type Post struct { Id int `orm:"pk;auto;column(post_name)"` Title string `orm:"column(title)"` Student *Student `orm:"rel(fk)"` } func init () orm.RegisterModel(new (Post)) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 package modelsimport "github.com/beego/beego/v2/client/orm" type Student struct { Id int `orm:"pk;auto;unique;column(student_id)"` Name string `orm:"column(name);size(20)"` ClassId *Class `orm:"rel(fk);column(class_id)"` Post []*Post `orm:"reverse(many)"` } func init () orm.RegisterModel(new (Student)) } func (s *Student) s.Post = append (s.Post, p...) }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 package modelsimport "github.com/beego/beego/v2/client/orm" type Class struct { Id int `orm:"pk;unique;auto;column(class_id)"` students []*Student `orm:"reverse(many)"` } func (c *Class) c.students = append (c.students, s...) } func init () orm.RegisterModel(new (Class)) }
然后我们去写main函数,在main函数中注册数据库驱动并插入数据。首先我们去新建一个数据库beego_orm以及用户beego
1 2 3 create database beego_orm; create user beego@localhost identified by 'beegogood'; grant all on beego_orm.* to beego@localhost;
然后我们链接数据库、新建两条记录分别插入两个表中:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 package mainimport ( "ORMDemo/models" _ "ORMDemo/routers" "fmt" "github.com/beego/beego/v2/client/orm" beego "github.com/beego/beego/v2/server/web" _ "github.com/go-sql-driver/mysql" ) func init () err1 := orm.RegisterDriver("mysql" , orm.DRMySQL) if err1 != nil { fmt.Printf("Error: %v" , err1) } err2 := orm.RegisterDataBase("default" , "mysql" , "beego:beegogood@/beego_orm?charset=utf8" ) if err2 != nil { fmt.Printf("Error: %v" , err2) } orm.RunSyncdb("default" , false , true ) } func main () o := orm.NewOrm() student1 := new (models.Student) student2 := new (models.Student) class := new (models.Class) post1 := new (models.Post) post2 := new (models.Post) student1.Id = 1 student1.Name = "Alice" student2.Id = 2 student2.Name = "Bob" post1.Title = "Hello World" post2.Title = "Beego orm" post1.Student = student1 post2.Student = student1 student1.AddPost(post1, post2) class.Id = 1 student1.ClassId = class student2.ClassId = class class.Join(student1, student2) o.Insert(student1) o.Insert(student2) o.Insert(post1) o.Insert(post2) o.Insert(class) beego.Run() }
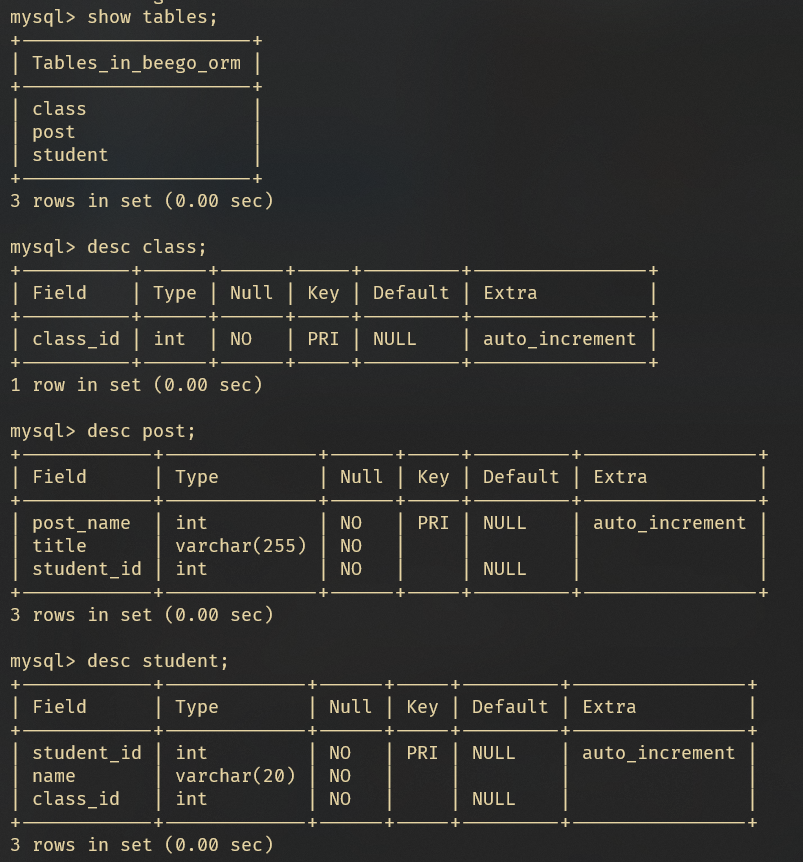
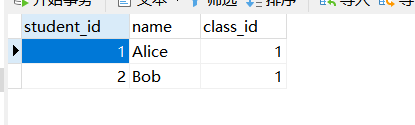
启动后我们看一下数据库的内容:
image-20210710194121221
image-20210710190431432
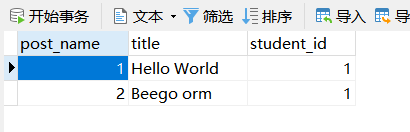
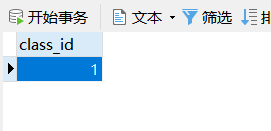
我们的数据也插进去了:
image-20210710194236049
image-20210710194242879
image-20210710194249760
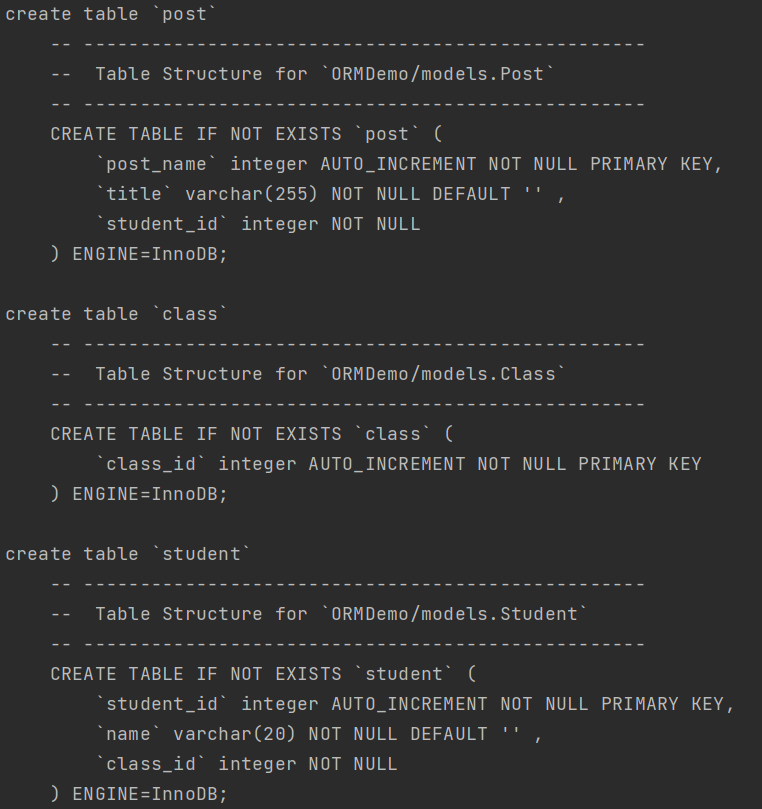
这里注意下,官方的教程里是有问题的,在注册了数据库驱动和数据库后,还要进行一个同步的操作:orm.RunSyncdb("default", false, true),否则你可能会提示表不存在什么的。控制台我们也可以看到后台的建表语句:
image-20210710190453057
beego默认是使用结构体中的Id字段来作为主键的。
重要字段
从上面的Demo中可以看出,Beego
ORM在处理字段映射关系的时候,使用的是两个反引号包括的形式,里面使用键值的方式来进行设置,每个属性使用;来进行分隔如:
1 `orm:"pk;auto;column(student_id)"`
这就好比JPA里的一些字段注解:
1 2 3 4 @Id private String Id;@Column private String name;
通过上述的方式就可以实现对字段进行一些设置,如pk代表Primary Key,auto代表自增长等等,也是比较方便的。
具体每一个字段的含义,请查看官方文档
XORM
基本概念
官方中文指导文档:首页 |
(gobook.io)
xorm的使用方法其实与beego
orm大同小异,只不过在列Column--也就是结构体的字段定义上有一点区别,使用xorm:xxx xxx xx来进行定义(注意是空格而不是分号)。官方给出的所有可用的选项如下所示:
字段 作用
name
当前field对应的字段的名称,可选,如不写,则自动根据field名字和转换规则命名,如与其它关键字冲突,请使用单引号括起来。
pk
是否是Primary
Key,如果在一个struct中有多个字段都使用了此标记,则这多个字段构成了复合主键,单主键当前支持int32,int,int64,uint32,uint,uint64,string这7种Go的数据类型,复合主键支持这7种Go的数据类型的组合。
autoincr
是否是自增
[not ]null 或 notnull
是否可以为空
unique或unique(uniquename)
是否是唯一,如不加括号则该字段不允许重复;如加上括号,则括号中为联合唯一索引的名字,此时如果有另外一个或多个字段和本unique的uniquename相同,则这些uniquename相同的字段组成联合唯一索引
index或index(indexname)
是否是索引,如不加括号则该字段自身为索引,如加上括号,则括号中为联合索引的名字,此时如果有另外一个或多个字段和本index的indexname相同,则这些indexname相同的字段组成联合索引
extends
应用于一个匿名成员结构体或者非匿名成员结构体之上,表示此结构体的所有成员也映射到数据库中,extends可加载无限级
-
这个Field将不进行字段映射
->
这个Field将只写入到数据库而不从数据库读取
<-
这个Field将只从数据库读取,而不写入到数据库
created
这个Field将在Insert时自动赋值为当前时间
updated
这个Field将在Insert或Update时自动赋值为当前时间
deleted
这个Field将在Delete时设置为当前时间,并且当前记录不删除
version
这个Field将会在insert时默认为1,每次更新自动加1
default 0或default(0)
设置默认值,紧跟的内容如果是Varchar等需要加上单引号
json
表示内容将先转成Json格式,然后存储到数据库中,数据库中的字段类型可以为Text或者二进制
comment
设置字段的注释(当前仅支持mysql)
此外,xorm还有几个自动映射的规则:
如果field名称为Id而且类型为int64并且没有定义tag,则会被xorm视为主键,并且拥有自增属性。 如果想用Id以外的名字或非int64类型做为主键名,必须在对应的Tag上加上xorm:"pk"来定义主键,加上xorm:"autoincr"作为自增。这里需要注意的是,有些数据库并不允许非主键的自增属性。string类型默认映射为varchar(255) ,如果需要不同的定义,可以在tag中自定义,如:varchar(1024)支持type MyString string等自定义的field,支持Slice,
Map等field成员,这些成员默认存储为Text类型, 并且默认将使用Json格式来序列化和反序列化。也支持数据库字段类型为Blob类型。如果是Blob类型,则先使用Json格式序列化再转成[]byte格式。如果是[]byte或者[]uint8,则不做转换二十直接以二进制方式存储。实现了Conversion接口的类型或者结构体,将根据接口的转换方式在类型和数据库记录之间进行相互转换,这个接口的优先级是最高的。 接口定义如下:
1 2 3 4 type Conversion interface { FromDB([]byte ) error ToDB() ([]byte , error ) }
如果一个结构体包含一个 Conversion
的接口类型,那么在获取数据时,必须要预先设置一个实现此接口的struct或者struct的指针。此时可以在此struct中实现BeforeSet(name string, cell xorm.Cell)方法来进行预先给Conversion赋值。
另外,结构体自动转换为对应的数据库类型时,下表显示了转换关系:
go type's kind value method xorm type
implemented Conversion
Conversion.ToDB / Conversion.FromDB
Text
int, int8, int16, int32, uint, uint8, uint16, uint32
Int
int64, uint64
BigInt
float32
Float
float64
Double
complex64, complex128
json.Marshal / json.UnMarshal
Varchar(64)
[]uint8
Blob
array, slice, map except []uint8
json.Marshal / json.UnMarshal
Text
bool
1 or 0
Bool
string
Varchar(255)
time.Time
DateTime
cascade struct
primary key field value
BigInt
struct
json.Marshal / json.UnMarshal
Text
Others
Text
Demo
直接上代码。
1 2 3 4 5 6 7 package modelstype Book struct { Id int `xorm:"pk autoincr"` Title string `xorm:"varchar(30)"` Author string `xorm:"varchar(30)"` }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 package mainimport ( "XormDemo/models" _ "XormDemo/routers" "fmt" beego "github.com/beego/beego/v2/server/web" _ "github.com/go-sql-driver/mysql" "xorm.io/xorm" ) var engine *xorm.Enginefunc main () var err error engine, err = xorm.NewEngine("mysql" , "beego:beegogood@/xorm_demo?charset=utf8" ) if err != nil { fmt.Printf("database setup failed %v" , err) } err = engine.Sync(new (models.Book)) book := new (models.Book) book.Title = "Beego" book.Author = "astaxie" affected, _ := engine.Insert(book) fmt.Printf("result: %v" , affected) beego.Run() }
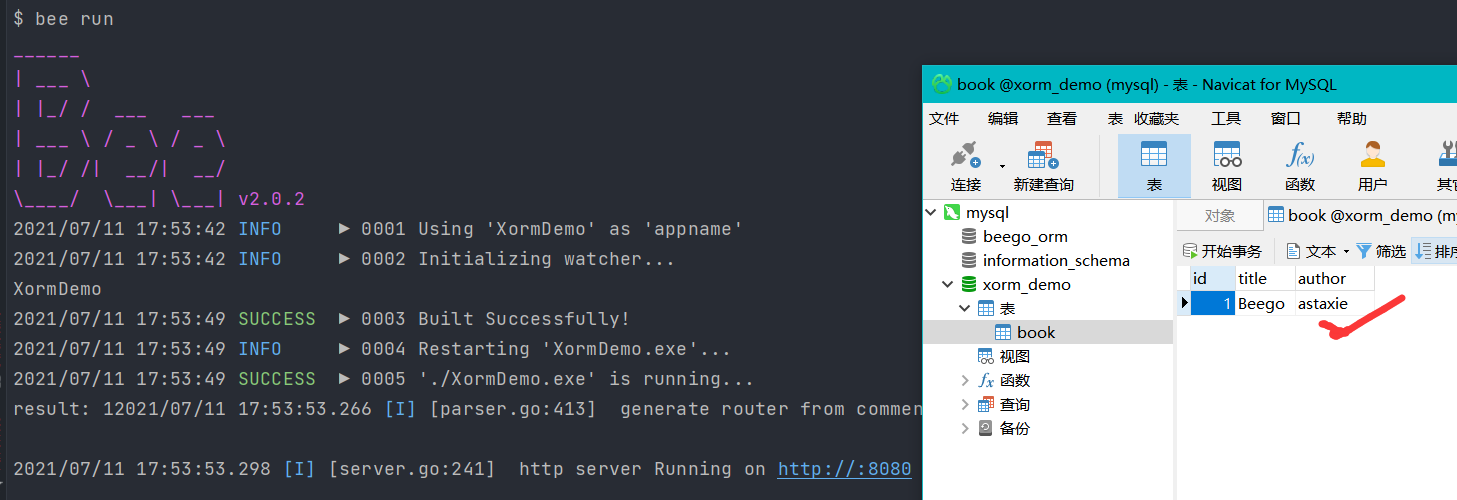
结果:
image-20210711175558003
这里有一个疑问,xorm怎么定义外键呢?比方说beego
orm里的reverse和rel关键字这个问题我还没有找到解答,暂时留一个问题在这里,如果解决了我会将上面的代码修改为多个表的例子
参考学习
xorm/xorm:
Simple and Powerful ORM for Go, support
mysql,postgres,tidb,sqlite3,sqlite,mssql,oracle,cockroach - README_CN.md
at master - xorm - Gitea: Git with a cup of tea
|
(gobook.io)