
Windows内存取证部分 (一)
准备工作
上一篇中大概介绍了一下Volatility的用法,因为目前较为成熟的内存取证书就只有那本The Art Of Memory Forensics,所以这一篇开始会跟着课本,以学习为第一目的,系统性的学习内存取证。
官方提供了一系列辅助学习的资料,下面是我收集到的资源,自行下载学习。
- 所需书本
- 官方内存样本以及资料,提取码:y2mu
- Windbg下载地址
此外最好自己装一个windows虚拟机,比如win7等,并配置所需工具。
怎么抓取内存
你可以使用下面的方式从自己的实体机或虚拟机中抓取内存来自己分析,或者用上面我提供的链接来下载官方的镜像样本。工具很多,这里提供常用的三种方法:
使用VMWare
如果你使用的是Vmware来做试验的话,只需要将虚拟机暂停,或者创建快照,就可以在对应目录下找到vmem文件了(虚拟内存文件)。,如下图所示:

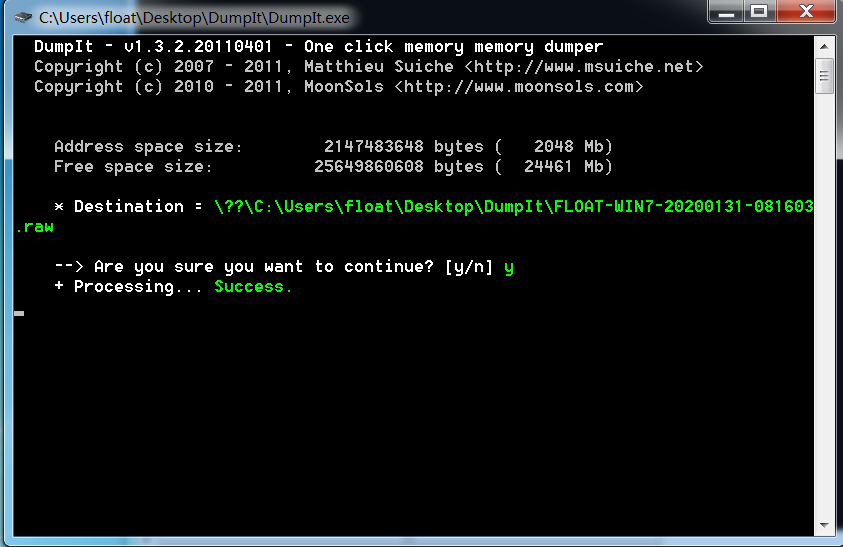
使用DumpIt
这个更无脑,免安装,直接放到对方机器,敲个y完事了。得到的结果是一个raw文件,具体用法和下载地址看这里,如图就是抓取完成:
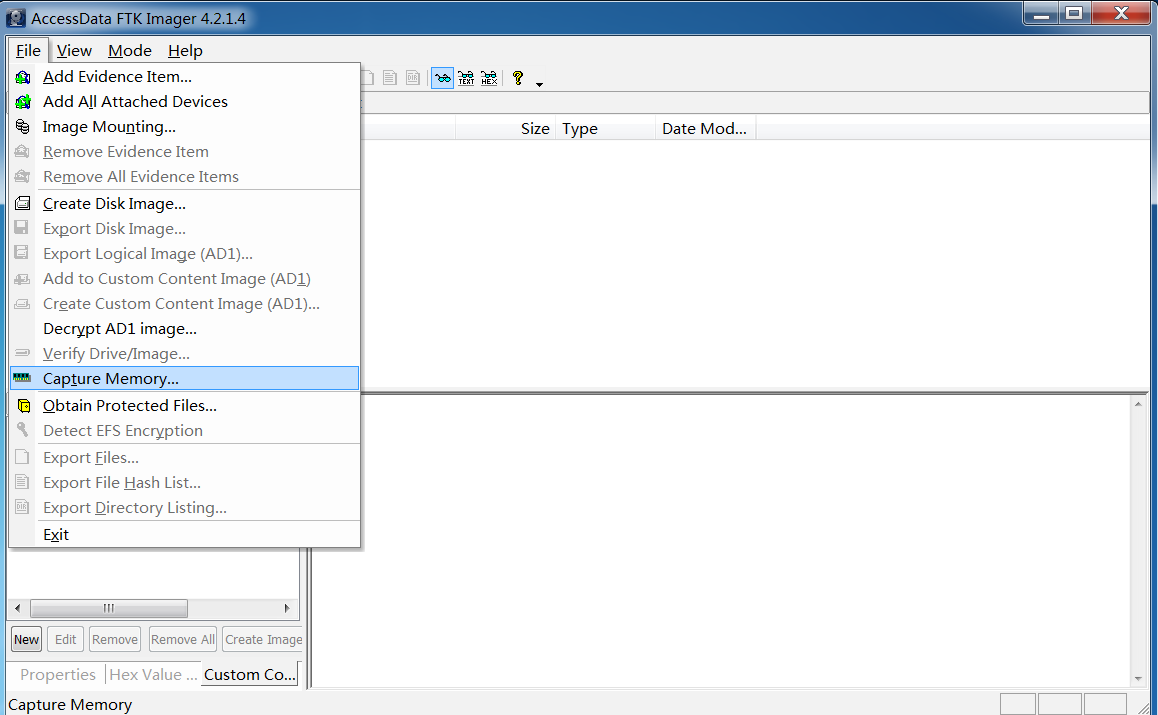
使用AccessData FTK Imager
打开FTK,File选项中有抓取内存的功能:
Windows Object And Pool Allocation (Windows对象和池分配)
Windows Executive Objects (Windows 可执行对象)
很多内存分析案例中都会牵扯到分析可执行对象,在windows中会有大量的C语言的数据结构,executive objects是其中一类的名称,来源是因为他们都被Windows Object Manager来管理(创建、维护、删除等),Windows Object Manager是Windows
NT内核的一个内核组件。注意,并不是所有的数据结构都是可执行对象(executive
objects),可执行对象是有他自己特殊的文件头的,其他数据结构是没有的;并且可执行对象是由对象管理器(Object
Manager)生成的,而其他的是由其他子系统生成的,如由TCP/IP栈(tcpip.sys)生成的。
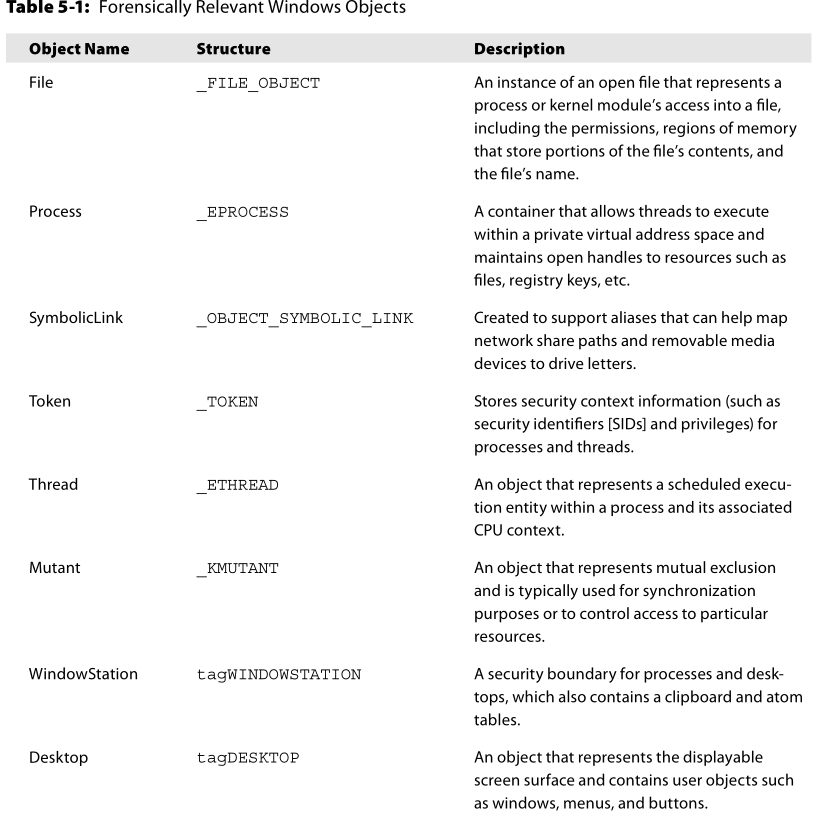
下面是一些与取证有关的可执行对象类型(executive object types),在Volatility中有相应的分析这些对象的插件:

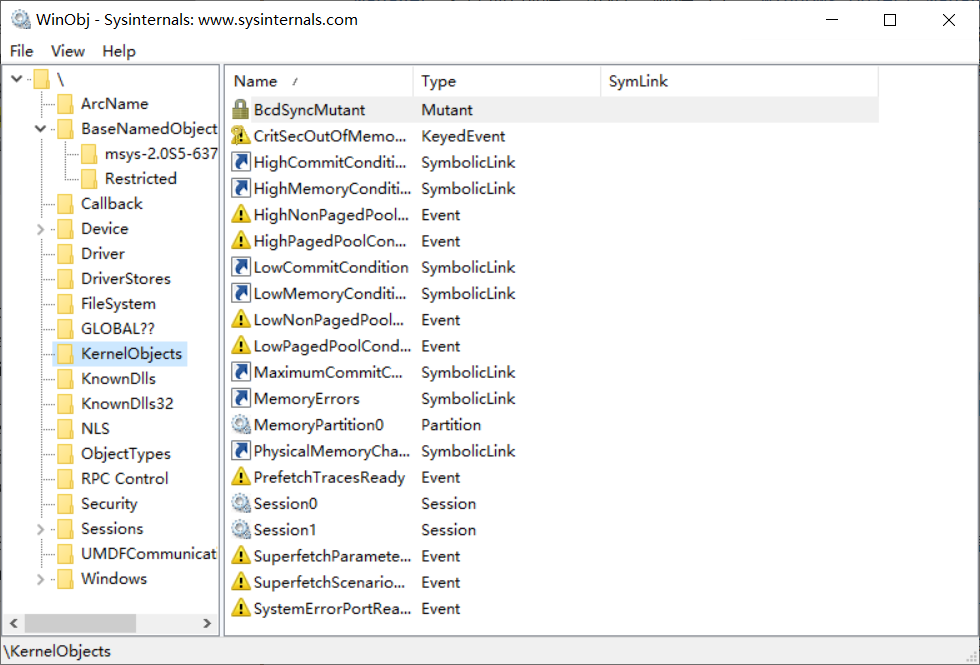
不同版本的Windows的对象类型会发生变化来支持新的特性,可以使用Sysinternals
Suite工具包中的winObj来查看(安利一下Mark
Russinovich大神写的windows工具包。如下图:
Object Header (windos 对象头部)
可执行对象类型的一个特点就是有一个object header(_OBJECT_HEADER类型),以及零个或多个可选的其他头部信息(optional
headers)。对象的头部(Object
header)会先于可执行对象的数据结构加载到内存中,同样地,可选的头部信息(optional
headers)也会一种方式(in a fixed order),先于一般头部信息(object
header)加载。这样的特点的结果是什么呢?就是加载到内存中的格式是可预知的(predictable),如下图:
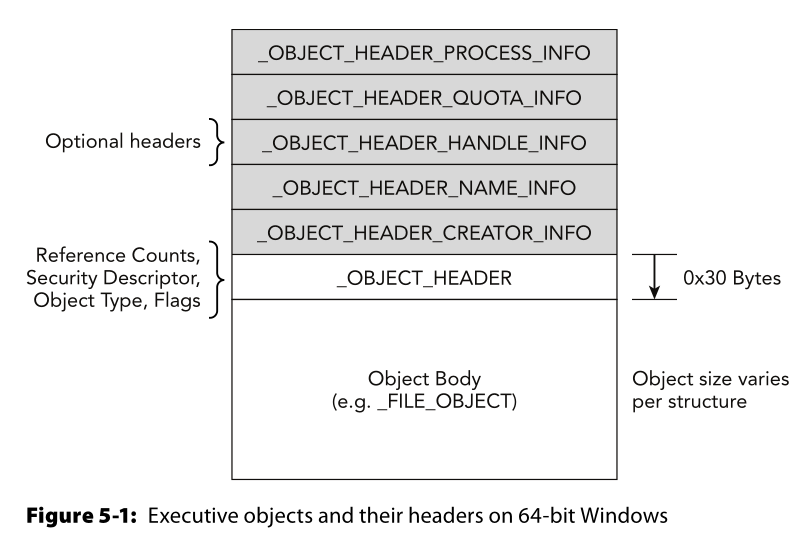
所以综上这种加载的特点,举一个栗子,比如一个File类型,它拥有一个_FILE_OIBJECT类型的数据结构,我们可以从这个数据结构中获取到它的_OBJECT_HEADER数据结构,或者反之亦然,因为这两个结构体在头部中是相邻的(上图),而对于_OBJECT_HEADER这个数据结构,它的大小不会应操作系统的不同而变化。
那么如何确定哪一个可选的头部信息是存在的呢?可以依靠对象头部的InfoMask信息。下面给出一个Win7上的对象头部的实例(自己可以在volshell中看,命令如下)。
1 | In [3]: dt("_OBJECT_HEADER") |
Optional Headers (windos 可选对象头部)
可选头部信息中包含了很多用于描述对象的元信息(metadata),因为是可选,所以不是所有的对象都拥有它,并且不同对象类型的实例也可能包含不同的可选头部信息,举一个栗子:操作系统内核不会跟踪每一个进程的负载情况(quota
stats),所以空闲(Idle)和系统(system)的进程虽然都属于_EPRROCESS类型的对象,但是他们两个是没有_OBJECT_HEADER_NAME_INFO这个可选头部的。但是匿名互斥锁是有这个头部的。
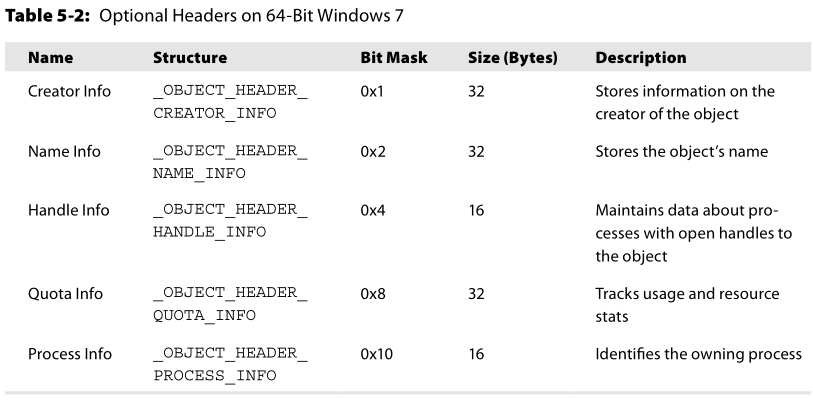
虽然可选头部信息很多,但是常分析的还是Name属性(见下图Name
Info)。下面的表是64位win7操作系统上的可选头部信息,如果Bit
Mask列的某一个值就是对象头部中的InfoMask的值的话,就说明这个头是有的。
Object Type Objects (windows 对象类型对象)
在上面的对象头部分析中,可以看到有一个参数TypeIndex,他代表了对象的类型,这个参数是在nt!ObTypeIndexTable(一个_OBJECT_TYPE的数组集合)中查找的索引(所以叫TypeIndex),这个参数对内存取证有很大用处,由(_OBJECT_HEADER.TypeIndex)你就可以判定这个对象的类型是什么。
举一个栗子:加入在一个进程句柄表中指向多个对象头部,为了确定这些对象都是什么类型,本来你需要去遍历上面说的表才能确定每一个对象的类型,但是现在你只需要查看每一个对象的_OBJECT_HEADER.TypeIndex值就可以了,通过这个索引你就可以计算出_OBJECT_TYPE的Name属性(见下面这张Win7x64的_OBJECT_TYPE的表):
1 | In [4]: dt("_OBJECT_TYPE") |
上述的这些属性中,TypeInfo和Key两个属性提供的线索可以告诉你两个W:
- Where(去哪里寻找,是分页的内存还是没分页的)
- What(一个特殊的四字节的标签tag)。
下面给出一个实例,镜像为使用DumpIt获取的内存文件,操作系统为Win7x64SP1,内存格式为raw。使用volatility的volshell进行说明,需要windbg工具((没有windbg也是可以的,后面我会提到))。
首先来看看volshell怎么使用,使用hh()命令可以查看用法
1 | # root @ kali in ~/Desktop [14:30:31] |
下面是每一个插件的用法: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22使用 addrspace() 获取虚拟或物理地址的数据结构
使用 addrspace().base 获取物理地址的数据结构
使用 proc() 获取当前进程对象
proc().get_process_address_space() 获取当前进程对象的地址
proc().get_load_modules() 获取当前进程对象加载的dll
addrspace(): 获取当前内核或者虚拟地址空间
cc(offset=None, pid=None, name=None, physical=False):用于改变当前shell的上下文
db(address, length=128, space=None): 以16进制dump的形式打印该地址处的字节
dd(address, length=128, space=None): 以双字的格式打印此地址内容
dis(address, length=128, space=None, mode=None) : 反汇编此处的代码
dq(address, length=128, space=None): 以四字的格式打印此地址内容
dt(objct, address=None, space=None, recursive=False, depth=0): 描述此对象或者显示它的类型
find(needle, max=1, shift=0, skip=0, count=False, length=128): (?)
getmods(): 内核模块生成器(脚本化)
getprocs(): 进程对象生成器(脚本化)
hh(cmd=None): 获取一个命令的帮助
list_entry(head, objname, offset=-1, fieldname=None, forward=True, space=None) : 遍历一个_LIST_ENTRY数据结构体
modules(): 以表格形式打印加载的模块
proc(): 获得当前进程对象
ps(): 以表格的形式打印当前的活动进程
sc(): 显示当前上下文
上述配置好了以后,再开始我们的示例。下面我们遍历一下内核空间内100个对象的对象类型,看看都是什么类型的。这里主要目的是熟悉volshell的使用以及澄清几个概念:
1 | kernel_space = addrspace() |
这段代码的含义是首先获取内核的地址;第二行设置了类型索引表的地址,后面要使用到该表;第三行实例化了一个对象,类型为数组,储存内容类型为指针,数组大小为100;第四行开始遍历这一百个元素,将每个指针解释为一个_OBJECT_TYPE类型的变量,如果他是有效的话就将它的名称、类型信息、Key值(这些都是对象类型对象的属性)打印出来,具体这些值的含义在本节开头我们已经提到了。
ObjectTypeIndexTable这个变量的值是类型索引表,它在windows内核是以一个全局变量导出的。打开windbg,查看这个变量的值。因为我没有学过windbg使用,所以这里只是简单使用,如果不能下载符号表的话,可以挂代理下载。使用dd ObTypeIndexTable命令就可以看到这个值了:
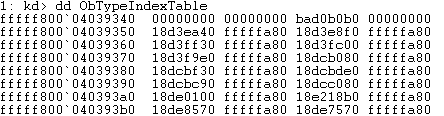
这里我的值是0xfffff80004039340,下面在volshell中运行这个脚本。先设置内核空间的地址以及变量的值,可以看到这个表是有内容的(如果是空的就说明你可能找错了,我第一次就是这样):
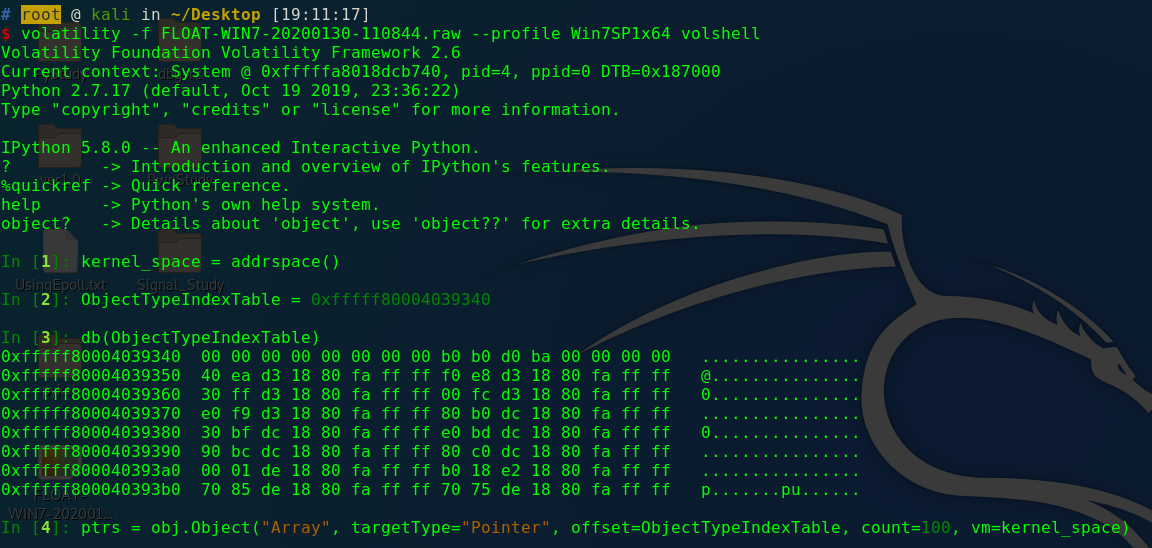
之后进行遍历循环:
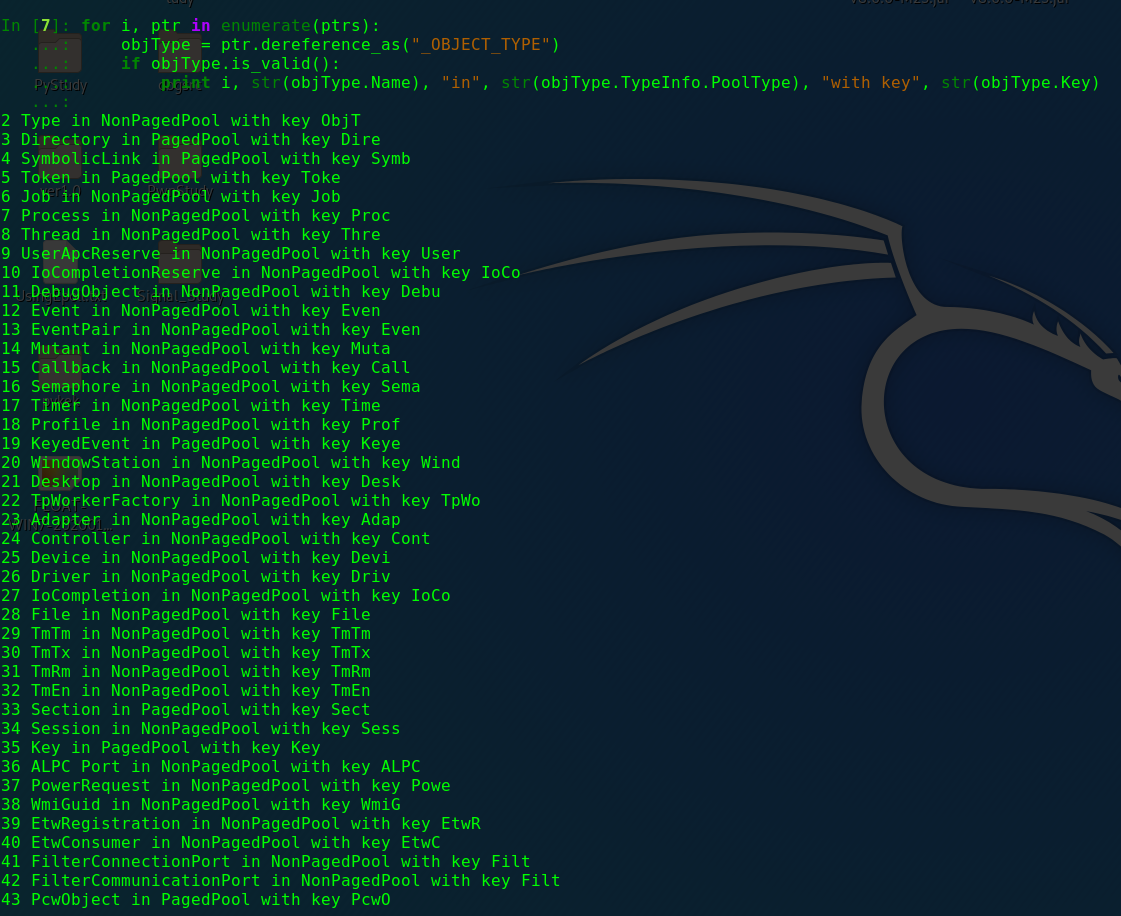
在结果中可以看到这几个特点:
1 | 1. 第一列总数不是100,说明不是每一个变量都是_OBJECT_TYPE类型的变量,即,他不是一个对象类型的对象 |
如果没有windbg的话,可以使用volatility的objtypescan插件来得出上述脚本的结果:
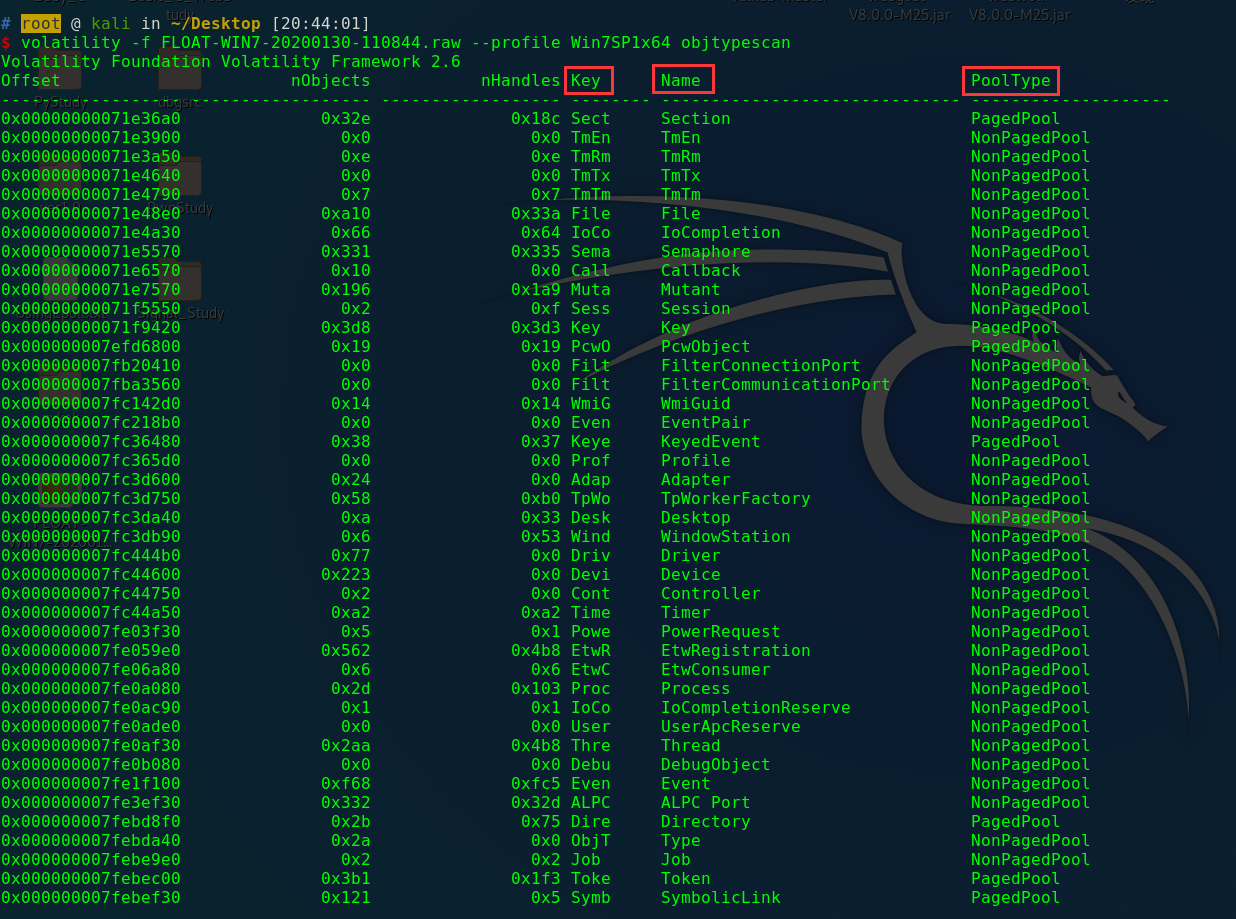
这个插件的结果和上面的结果是一样的,二者的区别是,使用nt!ObTytpeIndexTable是开始的地址开始进行扫描的,而volatility中的objtypescan插件结果的顺序是按照被发现的顺序出现的。
Kernel Pool Allocations (内核池分配)
内核池(kernel pool)是一段可分的内存,可以分为不同的小的块来储存内核模式的组件(NT、第三方驱动等)所需要的任何类型的数据
和堆类似,每一个分配的块都有一个头_POOL_HEADER,它包含着计数和调试的信息,这些信息可以帮助你找到不同块的内存所归属的驱动,而且在一定程度上可以帮助你推断数据结构的类型或者包含这些内存的对象。学习这部分除了对内存取证有很大帮助,在攻击方面也有帮助,如这篇文章Kernel
Pool Exploitation on Windows.7所述。
下面这张图是在Object Header的结构图的基础上增改的(红框是增加的):
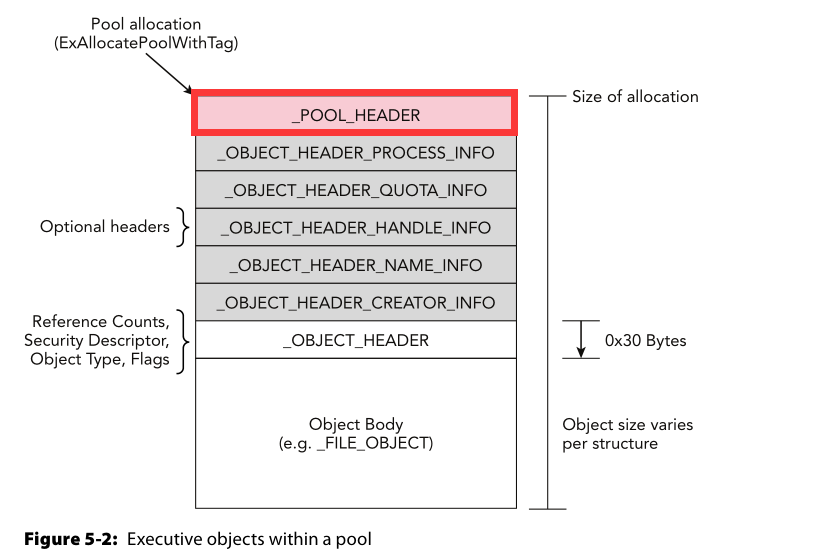
可以看到在可执行对象的头部信息中除了可选头部信息外还有一个_POOL_HEADER的数据结构信息。在Win7中_POOL_HEADER这个数据结构的结构是这样的:
1 | In [2]: dt("_POOL_HEADER") |
关键的变量值有这三个: 1
2
31. BlockSize: 块大小,代表了分配的对象大小,包括了池头部(pool header)、对象头部、和可选头部信息
2. PoolType: 这个池的系统内存的类型(分页?不分页?)
3. PoolTag: 一个4字节的、由ASCII字符组成的、唯一标识的、发生内存分配的代码路径(可以帮助将一些麻烦的块归属到它们的源)。在Win8和Win2012中,其中一个字符可能会被修改为保护位
Allocation API (分配API)
在实例化一个可执行对象(或者其他对象)时,一个足够容纳这个实例化的对象的、以及他的头部信息的内存块会从操作系统池中被分配。
实现这个分配的API是ExAllocatePoolWithTag,他的函数原型是这样的:
1
2
3
4
5PVOID ExAllocatePoolWithTag(
_In_ POOL_TYPE PoolType, //要分配的系统内存的类型,0代表不分页,1代表分页
_In_ SIZE_T NumberOfBytes,//要分配的大小,以字节为单位
_In_ ULONG Tag
);_OBJECT_TYPE.Typeinfo.PoolType这个值来查看具体。也有其他的标志位(_POOL_TYPE数据结构)来查看一段内存到底是可执行的,还是缓存对齐的,还是其他的,学习链接。
-
对于第二个参数,它决定了调用ExAllocatePoolWithTag这个函数的驱动要求分配的数据大小。内核中的函数ObCreateObject会最终来执行所有可执行对象的创建。举个栗子吧,假如说你要申请一个EPROCESS类型的对象,他的大小是1232字节(win7x64),然后你在加上_OBJECT_HEADER和其他可选头部信息的大小,最终的字节数就是你调用这个函数的第二个参数的值。
-
对于第三个参数,他是一个4字节的、由ASCII字符组成的、唯一标识的、发生内存分配的代码路径。对于可执行对象来说的话,这个标签是由_OBJECT_TYPE.Key这个属性派生的,二者都是4字节,所以同一个类型的对象,他们的Tag参数是一样的。
一个分配实例
下面举一个栗子,看看一个进程在创建一个新的文件时是怎么进行的:
1
2
3
4
5
61. 当前进程调用CreateFileA(ASCII格式)或者CreateFileW(Unicode格式),这两个函数都是kernel32.dll中的函数。
2. CreateFileA或者CreateFileW函数使用了ntdll.dll库,这个库随后会调用内核函数NtCreateFile。
3. NtCreateFile函数会调用ObCreateObject函数来申请一个新的FIle类型的对象。
4. ObCreateObject函数会计算_FILE_OBJECT结构体的大小,包括对象的可选头部信息的空间空间。
5. ObCreateObject函数查找File对象的_OBJECT_TYPE数据结构,并决定是放在分页内存还是不要分页内存,以及确定4字节的tag
6. 调用ExAllocatePoolWithTag函数,使用上面计算出的三个参数:对象大小、内存类型、tag_FILE_OBJECT类型的对象,并且这次分配会被一个4字节的tag来唯一标识。当然之后还会有一个指向该对象的指针被添加到该进程的句柄表中、操作系统全局的池中标签跟踪数据库(tag
tracking
database)也会进行相应的更新、该对象中其他的属性也会被初始化,如:权限(读、写、shan),文件的创建路径。
另外补充一点:并非使用相同大小、tag值、内存类型的对象jiu就会被分配到连续的内存中,这么说是因为windows会尝试将大小近似的对象放在一起,前提是没有可用的空闲块来满足请求的大小了,内核会从下一个大的组中来选择一个块用于分配。这样的结果就是你会看到同一类型的对象分散在windows的池中。此外,这样的分配特点会导致小的数据结构占用了一个用于储存大的数据结构的内存块,形成了一种松散的结构(slack space),如果没有适当的清理内存的话。详细参考这篇文章The Impact of Windows Pool Allocation Strategies on Memory Forensics
De-allocation and Reuse (释放和重用)
在上述的进程创建文件的例子中,这个被创建的文件的相关数据结构_FILE_OBJECT的生存时间(在内存中的存在时间),取决于很多因素。这里讨论下释放和重用(De-allocation and Reuse)
在这些因素中,唯一的、最重要的因素是这个进程结束读或写新文件时(通过调用CloseHandle)时,用了多久的时间,原文:how soon the process indicates (by calling CloseHandle ) that it is finished reading or writing the new file.,此时,如果或没有其他的进程使用这个文件对象,那么这块内存就会被释放会池中的空闲列表(free
list),这样这块内存就可以被重新分配以供他用。在等待被重新分配的时候或者等待写入新数据到内存时,大部分原先的(释放前)的_FILE_OBJECT的内容会保持完整(will
remain intact)。
究竟这块内存停留在完整的状态(上述状态)多久,取决于系统的活动等级(activity
level)。如果系统在猛烈的抖动(thrashing),并且后续请求的内存小于或等同于_FILE_OBJECT(这个例子中),那么就会被迅速的复写;否则这个对象就会生存几天或者几个星期---除非创建这个文件的进程结束了。
注意:当一块池的内存被释放的时候,并不是直接被复写了,而是简单的标记为了free。这对于硬盘取证(disk
forensics)也是一样的,当一个NTFS的文件被删除时,只有主文件表(Master File
Table,
MFT)会相应的改变状态,而文件的内容会保持不变---直到该分配的簇(sectors,分配是按簇分配的,如NTFS中一个簇是4096字节)被重新分配给了新的文件,并且发生了写事件。基于此,我们可以在已经被操作系统释放的内存中找到可执行对象。这样你就获得了在内存中查找不仅是当前常用的可执行对象,也可以查找过去存在过的资源。
Pool-Tag Scanning (池标签扫描)
池标签扫描,也叫池扫描(pool-scanning),是根据上面提到的_POOL_HEADER.PoolTag来进行分配查找的方法。
举一个栗子,为了定位一个进程对象,你可以找内核符号表(Kernel
Symbol)中的活动进程链表PsAcvtivePeorecssList(一个双向链表,保存着系统中所有进程的EPROCESS结构),然后遍历这个进程表。或者,使用池扫描的方法,他会翻整个内存文件,去查找Proc标记(与_EPROCESS相关的四字节标记)。使用后者方式的优点是你可以从表中发现一些历史条目(不再运行的进程),或者可以找到一些rootkit的痕迹(比如Direct
Kernel Object Manipulation ,DKOM)
但是你也不能全靠个tag来决定,否则会有大量的错误。所以Volatility内建了一个更牛逼的"签名"来帮助你分辨内存中你想要的分配单元,原理就是前面小节叙述的。比如分配单元的大小、内存的类型(分没分页)都能帮助减小错误。假如你要找个100字节的_EPROCESS结构体,但是你针具标签,却找到了一个30字节的单元,那显然是不对的。除了tag、大小、内存类型外,Volatility的pool-scanning还支持自定义一些约束来帮助搜索。比如你可以加个时间戳。
Pool Tag Sources (池标记源)
下面这张表Volatility通过pool
scanning来查找指定可执行对象的标准,第四列的最小大小都添加了_EPROCESS(对于process对象)、_OBJECT_HEADER、以及_POOL_HEADER。最后一列是对应的插件,经常会使用到.
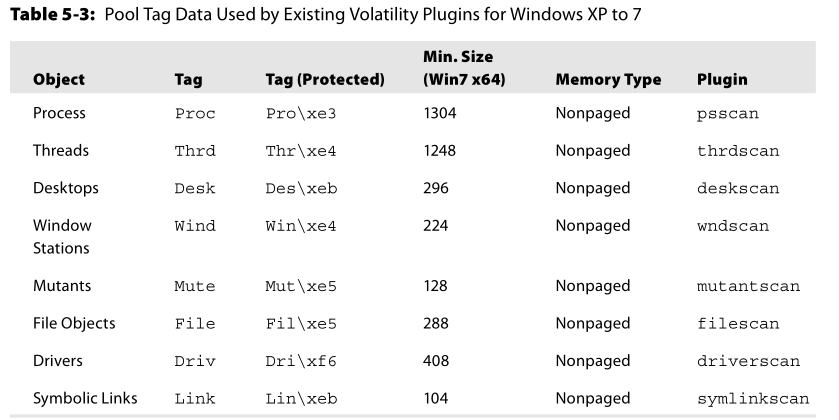
但是上面这些数据不是固定的,当windows有新版本出来的时候,都可能要修改,而且如果有恶意的内核驱动从池中申请空间来存放它的数据(如:配置信息,命令和控制数据包,需要隐藏的系统资源的名称等等)。所以你可能需要自己修改机制来包含新的标准。
此外,注意一下上表中的第三列。关于内核池标记最不常见的一个复杂特性就是受保护位(the
protected
bit).当我们通过ExFreePoolWithTag释放一个内核池的时候,我们必须设置跟当初申请空间时所用的ExAllocatePoolWithTag一样的标记。这项技术是操作系统用来防止驱动程序意外释放内存而设计的.如果传递给释放函数的标记不匹配,那么系统将抛出一个异常。这对与内存取证来说有很大的影响,因为这样的话我们就需要寻找受保护的内核池标记。
内核池标记中受保护的位并不是所有的内存分配都会设置,仅限与某些执行体对象类型.此外,从Windows 8和Windows Server 2012开始,貌似内核池标记中受保护位取消了。关于受保护的位更详细的信息可以参考这篇文章
Pooltag File
正如之前所提到的,微软创建池标记是为了调试和审计的目的。因此,Windows驱动开发包(DDK或者WDK)和Windows调试工具的安装目录中可以找到一个名为pooltag.txt的文件,这个文件我们可以用于查找。举个栗子:给定一个池标记(pool
tag),我们就可以确定该内存分配的目的以及拥有这块内存的内核驱动。因为该文件中包含有描述信息,所以我们也可以从诸如"进程对象"(process
object)或者"文件对象"(File
object)这样的关键字入手,进而找出其池标记。
下面给出一个pooltag.txt文件的部分内容,你可以在你windbg的triage文件夹中找到这个文件:
1 | rem |
在斜线标注的地方指出:进程对象的标签是Proc,由nt!ps来分配,nt!ps是NT的进程子系统。得到了这个信息后,你还需要找到近似的分配大小以及内存的类型(分页?不分页?)。
在这个网址中你也可以找到这个文件,但是里面的内容任何人都可以提交,所以不一定准确,windbg安装目录下就有这个文件。
PoolMon Utility (内存池监视器)
PoolMon (poolmon.exe) 内存池监视器,显示的操作系统从分页系统收集有关内存分配数据和非分页的内核池和用于终端服务会话使用的内存池。 按池分配标记分组数据。驱动程序开发人员和测试人员通常使用 PoolMon 检测内存泄漏时不创建新的驱动程序、 更改驱动程序代码中,或强调该驱动程序。 此外可以使用 PoolMon 测试的每个阶段中可查看分配和 free 操作的驱动程序的模式,并以显示该驱动程序使用在任何给定时间的池内存量。
上述对PoolMon的描述来自微软官方说明。poolMon在DDK(Micrsoft's
Driver Development,
DDK,也叫WDK)中可以找到。它会报告系统中使用的,关于池标签实时的更新,以及以下信息:
1
2
3
4
5内存类型(是否分页)
分配数量
空闲数量
分配占用的字节的总数
平均每一个分配占用的字节数C:\Program Files (x86)\Windows Kits\10\Tools\x64路径就可以看到该工具。使用工具的-b选项可以以字节的格式整理数据,将最对内存敏感的标签先列出来,下图是我在win10上的结果:
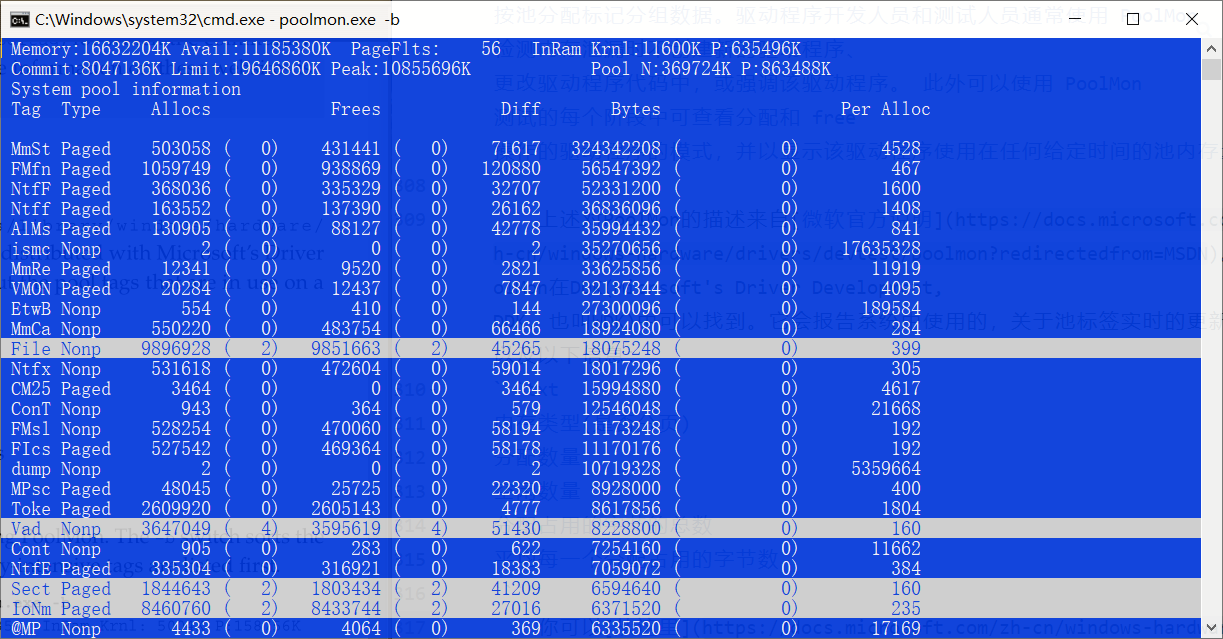
对我我这里的截图来说,我当前MmSt标签是在比特数量(Bytes列)排序中是第一个,从系统开始到截图这一刻,这个标签调用了503058次exAllocatePoolWithTag函数(第三列),其中431441个池被释放了,二者的差为71,617(Diff列),即当前有71617个池被分配,他们总共占用了324342208个字节的内存(大概324.3MB),平均算下来一个池占了内存约为4528字节。
在第一个白色的杠下面第二杠有一个CM25标签,大概占了内存16MB,CM的意思是配置管理器(Configuration Manager),它是一个包含着windows注册表的内核组件。所有这些CM标签加起来的总和大概就是你注册表的大小,但是你不可能把他们都从内存中dump出来,因为储存在分页内存中的标签它的数据可能会映射到磁盘上,而你手头只有内存。
此外,第一个白色的杠是一个File标签,它储存着一个_FILE_OBJECT数据结构,可以看到大概9900000个池被创建,它的特点是每次文件被打开或者创建的时候都会分配一个_FILE_OBJECT结构体。但是因为文件对象都相对小一点,所以可以看到实际上只有45265字节被真正分配,平均每个池399字节。
左手一个poolMon右手一个pooltag.txt,基本你就掌握了池标签,相应描述,所属内核驱动,分配大小,内存类型这些信息了。这些信息就足够你开始扫描内存导出文件,查找分配的实例了。
为了学习方便,你还可以在windbg中使用!poolfind命令来查找你想要的标签并告诉你内存类型和分配的大小,比如书上的这个栗子:
1 | kd> !poolfind Proc |
从上面的信息你可以看到,有六个被分配了的进程,有两个被标记为free,其中一个free的大小和其他一样,都是430,而另一个是10。所以你可以推断这个位于0xfffffa800138f7a0的块可能包含这一个终止的进程_EPROCESS数据结构,而0xfffffa800153ebd0的那个块可能被重用了。
Pool Tracker Tables (池跟踪器表)
上面的poolMon牛逼是牛逼,问题是内存取证万一咱只有内存,么得实体机咋跑poolMon.exe?所幸的是内存中其实是包含了一些静态数据,它们都会被poolMon读取,那怎么不通过poolMon读取这些数据呢?它们储存在一个内核调试数据块中(_KDDEBUGGER_DATA64),这个块同样也储存了活动的进程和加载的模块的列表。PoolTrackTable表实际上指向了一个数组,这个数组中储存着一些名为_POOL_TRACKER_TABLE的数据结构,这个数据结构中,每一个独特的吃标签都会被记录,使用volshell查看一下,还是Win7SP1x64:
1 | In [2]: dt("_POOL_TRACKER_TABLE") |
可以看到每一个跟踪器表都有一个4字节的Key属性,剩下的属性根据内存的类型分为了两类,分别告诉你了分配的数量、释放的数量、占用总字节数。虽然内存文件是一个时刻的,并不能项poolMon那样实时的更新数据,但是你至少能判断出来它在这一时刻(内存导出时)的状态,下面使用volatility的pooltracker插件来查询几个特定的可执行对象标签,Np代表不分页,Pg代表分页:
![]()
从结果来看,这四个标签的对象都在非分页的内存中,从上面的结果你可以得到比如这样的信息:对于Thre标签(Thread
Object),它平均池大小为252544/(23747-22436)=1311字节。所以如果要查找所有的包含线程对象的分配池的话,你的查找约束条件就是这样的:1.是Thre标签;2.大小至少是1311字节。
此外这里有几个使用pooltracker插件的小技巧,如果你要显示更详细的信息的话,可以带带上--tagfile参数,参数值是你的pooltag.txt文件,这样输出就会显示上面结果没有显示的描述以及所属驱动了。比如这样(我用的win7的pooltag.txt,他比win10的小):
![]()
注意:因为windows在XP和2003之前(包括他们)不会将这些统计数据写到池跟踪器表中,所以这个插件只适用于Vista及之后的操作系统。此外,池跟踪表也有它的限制性,他只会统计标签的使用情况结果,不会记录每一个标签的所有分配池的地址
Building a Pool Scanner (建立一个池扫描器)
DIY走起
在上面的小节中可以看到,Volatility为常见的tags都有自己插件,比如psscan,thrdscan,filescan等等。同时Volatility也为我们提供了一个基础的叫PoolScanner类,来帮助我们自己DIY一个扫描器(比如可以自己指定查找什么标签,指定查找的分配池大小,分配的内存的类型等等),以及一个叫AbstractScanCommand的类给我们提供一个池扫描器应有的命令行选项。
Extending the PoolScanner (扩展PoolScanner插件)
下面的代码是psscan插件(扫描进程对象的池扫描器)的一个必要配置文件,可自行查看源代码(/usr/lib/python2.7/dist-packages/volatility):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
161 class PoolScanProcess(poolscan.PoolScanner):
2 """Pool scanner for process objects"""
3
4 def __init__(self, address_space, **kwargs):
5 poolscan.PoolScanner.__init__(self, address_space, **kwargs)
6
7 self.struct_name = "_EPROCESS"
8 self.object_type = "Process"
9 self.pooltag = obj.VolMagic(address_space).ProcessPoolTag.v()
10 size = self.address_space.profile.get_obj_size("_EPROCESS")
11
12 self.checks = [
13 ('CheckPoolSize', dict(condition = lambda x: x >= size)),
14 ('CheckPoolType', dict(non_paged = True, free = True)),
15 ('CheckPoolIndex', dict(value = 0)),
16 ]PoolScanProcess类继承了poolscan.PoolScan类,所以方法可以从父类继承,如果你要自定义一个扫描器的话,只需要做如下修改:
1. Structure
name:修改第七行的数据结构名称。它会告诉池扫描器要扫描的数据结构类型
2. Object
type:修改第八行的可执行对象类型。当扫描器扫描可能的池对象时,他会看这个对象的_OBJECT_HEADER.Name属性的值是不是这里设定的值。如果不包含可执行对象的话,这里的值可以为空(比如网络连接和sockets)
3. Pool
tag:修改第九行的池标签。假如你要找Proc标签的对象,这里不能直接写个Proc,而是使用了一个根据不同的profile的容器来获取的,因为不同操作系统版本的标签可能会发生变化
4. Allocation
size:修改第十行的分配大小,基于最小的要查找的对象的大小(比如_EPROCESS的大小)。这里的值也不是直接写的,因为不同的操作系统类型会影响这个值,尤其对于32位操作系统和64位操作系统,大小的约束在13行。
5. Memory
type:修改第十四行的内存类型。这里只有non_paged和free两个值的键值为true,那么扫描器会扫描非分页区和释放了的内存中的池,并跳过在分页内存中的结果。
Extending AbstractScanCommand (扩展选项)
上一节中已经看了一个扫描器是怎么初始化的,下一步就似乎创建一个插件,由它来加载扫描器并在终端中展示结果,下面是psscan的插件代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
241 class PSScan(common.AbstractScanCommand):
2 """Pool scanner for process objects"""
3
4 scanners = [poolscan.PoolScanProcess]
5
6 def render_text(self, outfd, data):
7 self.table_header(outfd, [('Offset(P)', '[addrpad]'),
8 ('Name', '16'),
9 ('PID', '>6'),
10 ('PPID', '>6'),
11 ('PDB', '[addrpad]'),
12 ('Time created', '30'),
13 ('Time exited', '30')
14 ])
15
16 for pool_obj, eprocess in data:
17 self.table_row(outfd,
18 eprocess.obj_offset,
19 eprocess.ImageFileName,
20 eprocess.UniqueProcessId,
21 eprocess.InheritedFromUniqueProcessId,
22 eprocess.Pcb.DirectoryTableBase,
23 eprocess.CreateTime or '',
24 eprocess.ExitTime or '')common.AbstractScanCommand父类,在第四行的scanners变量,其值时上面的poolscan.PoolScanProcess类,这里的值由你要寻找的对象的类型决定。7-14行生成了表的头部,就是下图中空框这一行:

16-24行将扫描器得到的结果放入表中,就是上图中的每一行结果,他们都是_EPROCESS类型对象(在本例中)。通过继承AbstractScanCommand类,你的新的插件就拥有了用户使用不同的命令行选项来调整的能力,比如你可以用--help指令看下帮助:
1 | (省略) |
比如我只扫描一段区间的:

PoolScanner Algorithm (池扫描器算法)
所有池扫描器的父类---PoolScanner类使用了下面这个图的逻辑:
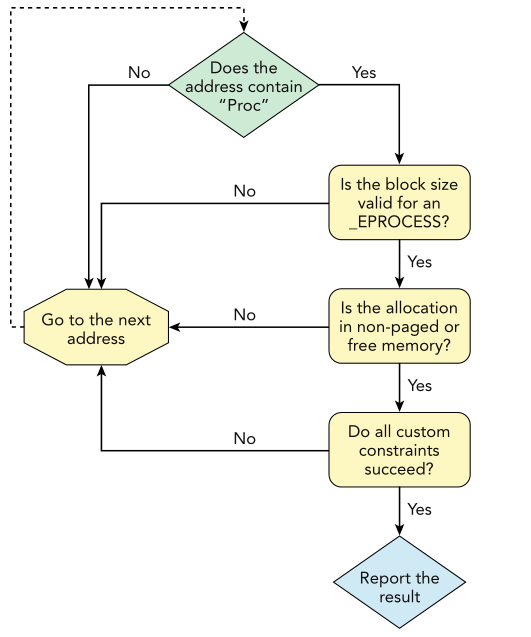
图中的检查步骤都是前面小节学习的内容。即每到下一个地址,就检查这个地址中的池对象是否包含标签Proc,是的话接着判断他的大小是否有效,是的话接着判断是否是在不分页或空闲内存(内存类型)中,是的话接着使用用户自定义的约束进行判断,最终得到结果。
对于psscan插件,如果你设置了-V选项,那么扫描器就会从内核的页表中遍历扫描所有的页,否则的话(无-V选项使用物理地址),扫描器会从偏移地址0开始进行扫描,直到内存文件的末尾,这样可以保证结果的正确性。
Finding Terminated Processes (搜索终止进程)
在官方给的windows镜像中的sample003.bin中,可以看到psscan的结果中有的进程是有退出时间的,比如下面这个cmd.exe,持续了2分10秒:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15$ volatility -f sample003.bin --profile=WinXPSP2x86 psscan
Volatility Foundation Volatility Framework 2.6
Offset(P) Name PID PPID PDB Time created Time exited
------------------ ---------------- ------ ------ ---------- ------------------------------ ------------------------------
0x000000000181b748 alg.exe 992 660 0x08140260 2008-11-15 23:43:25 UTC+0000
0x0000000001843b28 wuauclt.exe 1372 1064 0x08140180 2008-11-26 07:39:38 UTC+0000
0x000000000184e3a8 wscntfy.exe 560 1064 0x081402a0 2008-11-26 07:44:57 UTC+0000
0x00000000018557e0 alg.exe 512 672 0x08140260 2008-11-26 07:38:53 UTC+0000
0x000000000185dda0 cmd.exe 940 1516 0x081401a0 2008-11-26 07:43:39 UTC+0000 2008-11-26 07:45:49 UTC+0000
0x00000000018a13c0 VMwareService.e 1756 672 0x08140220 2008-11-26 07:38:45 UTC+0000
0x00000000018af448 VMwareUser.exe 1904 1516 0x08140100 2008-11-26 07:38:31 UTC+0000
0x00000000018af860 VMwareTray.exe 1896 1516 0x08140200 2008-11-26 07:38:31 UTC+0000
0x00000000018e75e8 spoolsv.exe 1648 672 0x081401e0 2008-11-26 07:38:28 UTC+0000
0x00000000019456e8 csrss.exe 592 360 0x08140040 2008-11-15 23:42:56 UTC+0000
(省略)
但是你使用池标签扫描是可以发现他们的(psscan就是池标签器)。具体的应用就是,假如这是一台内网设备,如果你发现存在过Ping或者ifconfig这类命令,那说明攻击者可能在这台机器上对网段进行了描,这个例子也是池扫描技术经常应用的地方。后面我们还会接触到运用池扫描技术来检测内核级别的rootkit。
Limitations of Pool Scanning (池扫描技术的限制性)
虽说他是个很牛逼的方式,无需借助操作系统就可以扫描出对象,但是他有下述的几个限制性。
Non-mailcious Limitations (误判)
下面这几种情况可能会被误判为是对证据的恶意的篡改:
- 没标签的池内存:虽然微软推荐使用
ExAllocatePoolWithTag来让驱动和内核模式的组件来分配内存,但是这并非唯一的方式,使用ExAllocatePool也可以实现,只不过他被弃用了,但在很多windows版本上仍然是可用的。这种方式分配的内存不会带tag标签,对你的查找工作会造成困难。 - 假阳性(False positives):池扫描器的逻辑我们已经看过了,实质是一个基于经验判断的启发式算法,误报是难免的。
- 大的内存分配:池标签扫描技术不能扫描出超过4096字节的分配(后面会提到"Big Page Pool"大页池),不过所有的可执行对象都比它小。
- 没标签的池内存:虽然微软推荐使用
Malicious Limitations(Anti-Forensics) (反取证的限制)
下面这些反取证手段也会导致池扫描的误判:
1. 任意标签:驱动在分配内存时默认使用的标签时"Ddk "(后面有空格)。当操作系统或第三方代码没有指定标签时,就会使用这个标签。如果一个恶意驱动使用了"Ddk "作为它们的标签,内存块就会和其他块混合起来,难以分辨。 1. 伪造标签:这篇文章中提出,驱动可以创建一个表现的很像一个正常对象的,带有假标签的对象来误导取证人员。 3. 被操纵的标签:前面也提到了,微软创建池标记是为了调试和审计的目的,它们对于操作系统本身的稳定性并不重要。但是内核Rootkit可以修改池标签(或者_POOL_HEADER中的任何值,比如大小,内存类型等),这对操作系统没什么影响,但是会影响Volatility的扫描结果。 但是对于这些限制你也可以应变,比如使用其他手段来进行搜索,池扫描只是其中的一种,或者可以借助其他证据文件,比如检查流量包来确定是否发生过某一事件。
Big Page Pool (大页池)
前面提过,Windows内核会尝试将近似大小的分配放在一起,但是如果请求内存的大小超过了一个页的大小(4096字节,4KB),那么这个块就会由一个特殊的池来分配 --- 大页池(Big Page Pool)
在使用大页池分配的这种情况下,是不存在_POOL_HEADER结构的,所以池标签扫描会失败,因为压根就没有标签。
下图是小于4096和大于4096的内存的分结构,可以看到二者区别就是后者没有_POOL_HEADER头信息:
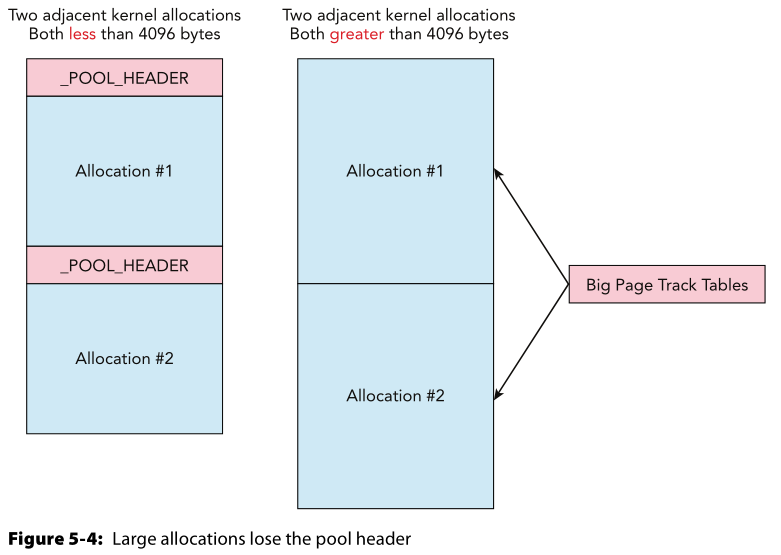
但是你只需要换一个角度就可以找到这个单元了,那就是查看大页跟踪表(big page track tables),它的条目会直接指向大页池中的对象。
Big Page Track Tables (大页跟踪表)
大页跟踪表和上面提到的池跟踪表是有区别的。池跟踪表(PoolTrackTable)适用于小的内存块(小于4096字节),其中储存着统计信息(分配数量、使用量等),但是它不会告诉你每一个分配的准确的地址,这一点在PoolTrackTable小姐提到了,这也是为什么需要遍历去扫描的原因。但是对于大页跟踪表,恰恰相反,它不储存统计信息,但是却包含了每一个分配的地址,如果你找到了大页跟踪表,就相当于你有了一张在内核内存中定位任何大的分配块的地图。
不过,内核符号nt!PoolBigPageTable指向的数组中,虽然储存了一些_POOL_TRACKER_BIG_PAGES的数据结构(每一个对应着一个大的分配块),但是它们不会被拷贝或导出到内核调试数据块(_KDDEBUGGER_DATA64)中(不像PoolTrackTable)。但是,你可以在nt!PoolTrackTable中的一个可预测的位置上找到它,因为这部分是会拷贝到内核调试数据块中去的。下面用volshell看一下win7SP1x64中大页追踪表的数据结构:
1 | In [10]: dt("_POOL_TRACKER_BIG_PAGES") |
第一个参数Va是Virtual
Address的缩写,它的值是一个指向分配块的基址的指针,第二个参数Key(4字节,0xc-0x8)就是pool
tag,而第三个参数PoolType就是内存的类型(是否分页),最后一个参数是分配的大小。
注意:虽然地第二个参数是poolTag,但是这个标签的位置是Va参数指向的位置,和分配的地址是完全不同的。而在对于小的分配(_POOL_TRACKER_TABLE),它的标签是储存在分配中的。这一点很好理解,上面的对比图中后者没有_POOL_HEADER头,而tag属性是储存在_POOL_HEADER中的(红框):

Bigpools Plugin (应用于大池扫描的插件)
为了从内存中得到生成大的内核池分配的信息(上述结构体信息),Volatility为我们提供了一个叫bigpools的插件,下面是部分结果:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19$ volatility -f FLOAT-WIN7-20200130-110844.raw --profile Win7SP1x64 bigpools
Volatility Foundation Volatility Framework 2.6
Allocation Tag PoolType NumberOfBytes
------------------ -------- -------------------------- -------------
0xfffff8a003c09000 CM25 PagedPool 0x1000L
0xfffff8a00458d000 CM31 PagedPoolCacheAligned 0x1000L
0xfffff8a0007ee000 CM25 PagedPool 0x4000L
0xfffff8a004a4f000 CM31 PagedPoolCacheAligned 0x1000L
0xfffff8a000cb0000 CM25 PagedPool 0x1000L
0xfffff8a004f11000 CM31 PagedPoolCacheAligned 0x1000L
0xfffffa8019cc2000 Cont NonPagedPool 0x1000L
0xfffff8a0053d3000 CM31 PagedPoolCacheAligned 0x1000L
0xfffff8a005895000 CM31 PagedPoolCacheAligned 0x1000L
0xfffff8a005d57000 CM31 PagedPoolCacheAligned 0x4000L
0xfffff8a006219000 CM31 PagedPoolCacheAligned 0x1000L
0xfffff8a005ce1000 CM31 PagedPoolCacheAligned 0x2000L
0xfffff8a001f42000 Obtb PagedPool 0x1000L
0xfffff8a0061a3000 CM31 PagedPoolCacheAligned 0x1000L
(省略)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19In [2]: db(0xfffff8a003c09000, length=0x1000L)
0xfffff8a003c09000 68 62 69 6e 00 50 23 00 00 10 00 00 00 00 00 00 hbin.P#.........
0xfffff8a003c09010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................
0xfffff8a003c09020 d8 ff ff ff 76 6b 0a 00 08 00 00 00 e8 4f 23 00 ....vk.......O#.
0xfffff8a003c09030 03 00 00 00 01 00 00 00 31 31 30 36 33 31 36 38 ........11063168
0xfffff8a003c09040 30 33 00 00 00 00 00 00 d8 ff ff ff 76 6b 0a 00 03..........vk..
0xfffff8a003c09050 08 00 00 00 70 50 23 00 03 00 00 00 01 00 00 00 ....pP#.........
0xfffff8a003c09060 31 31 30 36 33 31 38 39 30 30 00 00 00 00 00 00 1106318900......
0xfffff8a003c09070 f0 ff ff ff 00 00 70 00 00 00 00 00 00 00 00 00 ......p.........
0xfffff8a003c09080 e8 ff ff ff 78 4f 23 00 a0 4f 23 00 20 50 23 00 ....xO#..O#..P#.
0xfffff8a003c09090 48 50 23 00 00 00 00 00 e0 ff ff ff 76 6b 07 00 HP#.........vk..
0xfffff8a003c090a0 08 00 00 00 68 4a 23 00 01 00 00 00 01 00 2d 00 ....hJ#.......-.
0xfffff8a003c090b0 53 65 72 76 69 63 65 00 d8 ff ff ff 76 6b 0c 00 Service.....vk..
0xfffff8a003c090c0 14 00 00 00 70 52 23 00 07 00 00 00 01 00 30 00 ....pR#.......0.
0xfffff8a003c090d0 55 70 70 65 72 46 69 6c 74 65 72 73 31 00 30 00 UpperFilters1.0.
0xfffff8a003c090e0 d8 ff ff ff 76 6b 0f 00 4e 00 00 00 08 51 23 00 ....vk..N....Q#.
0xfffff8a003c090f0 01 00 00 00 01 00 41 00 44 72 69 76 65 72 50 61 ......A.DriverPa
0xfffff8a003c09100 63 6b 61 67 65 49 64 00 a8 ff ff ff 61 00 67 00 ckageId.....a.g.
0xfffff8a003c09110 70 00 2e 00 69 00 6e 00 66 00 5f 00 61 00 6d 00 p...i.n.f._.a.m.hbin和vk分别代表注册表HBIN块的签名和一些值。
有一个比较有意思的地方,作者提到根据他们的研究,分配基址的最后一位16进制数如果为1的话,就说明这块内存已经被标记为了free。下面我也实验一下,看是否如此。我查看下这几个块:
1 | 0xfffff8a001e1b001 CM31 PagedPoolCacheAligned 0x1000L |
可以看到有一个是不可读的状态,而另一个还是可读的。
作者的解释是不可读的那一个可能就是我们之前提到的,数据映射到了磁盘上的例子,因为他是位于分页的内存。而另一个则已经被重新分配并且重写了,因为它的数据已经没有hbin这个数字签名了。
Exploring Big Page Pools (深入搜索大页池)
刚才很多命令的结果都是部分结果,在一个系统中大页池可能会有成千的分配结果,你可以使用--tags来帮助你过滤,再结合一些管道来进行筛选,比如做一个简单统计:
1
2
3
4
5
6
7
8
9
10
11
12awk '{print $2}' bigpools.txt | sort | uniq -c | sort -rn
9929 CM31
2753 CM25
1368 Cont
878 CMA?
322 CM53
183 MmRe
141 MmSt
123 Obtb
91 CM16
81 Ntf9
(省略)
Pool-Scanning Alternatives (池扫描备选方案)
到这里我们已经学习了内存区正中的池标签扫描(pool tag scanning)优点和缺点以及原理方法了,下面讨论几个备用方案。
Dispatcher Header Scans (调度器头部扫描)
许多执行体对象(如进程、线程、互斥锁)都是可同步的。这意味着其他线程可以同步、或等待这些对象的执行、结束、或者执行其他类型动作,为了实现这个功能,操作系统内核会将一个对象的当前状态储存在一个叫_DISPATCHER_HEADER的子结构(substructure)中,每一个执行体对象的开头都会有这个子结构。
此外这个结构体内还包含着一些与windows版本有关的信息,也可帮助你确定操作系统的profile值。更多关于调度器头部信息在内存取证取证中的用途,参考Searching for Processes and Threads in Microsoft Windows Memory Dumps
下面是volshell中查看Win7SP1x64中_DISPATCHER_HEADER的结果:
1 | In [1]: dt("_DISPATCHER_HEADER") |
作者指出,对于Absolute和Inserted这两个变量,在win2K,2k3,XP中都是0,而Type和Size变量都是硬编码的形式写死了对象的类型和大小,比如WinXPx32,Type变量值为3代表进程,对应大小为0x1b,四字节签名为1b。你可以使用这个签名,以类似池tag扫描的方式进行扫描,这也是早期内存取证的一款名为PTFinder的工具工作原理。
但是调度器头扫描的方法只能扫描到同步了的对象,假如一个对象没有进行同步,那么它就没有_DISPATCHER_HEADER这个头部信息,这样你就不能找到_FILE_OBJECT类型的实例了。
这个方法只作为介绍,没有太大实践价值,Volatility中的pspdispscan插件就是对应这个方法(2.6版本中已经去掉了,作为一个POC),但只限于32位WindowsXP。
Robust Signature Scans (增强型签名扫描)
池头部信息和调度器头部信息对于操作系统来说都是不重要的,所以恶意的修改它们可以逃过基于标签的扫描方法,同时不对操作系统造成影响。所以有另一个对抗这种恶意修改的搜索对象的手段,详细描述在这篇文章:Robust Signatures for Kernel Data Structures。大概就是研究要查找的结构体中,那些信息的修改会导致操作系统的崩溃,再依据这些信息来进行搜索,这样敌手就不能随意修改了。这对于搜索被内核级别的rootkit隐藏的进程或线程有参考价值。
在Volatility
1.3版本中可以使用psscan3插件进行增强型的签名扫描,但是最新版本中不包含该插件。可以自行在这里下载psscan3
Summary 总结
本篇主要讨论的是windows对象管理器(Windows Object Manager)在创建和删除一些主要类型对象(进程、文件、注册表键值等)时的作用,这些都是取证时要依赖的对象。
本篇主要学习了具体Volatility在实现搜索这些对象时使用的方式以及原理,我们也可以看到,虽然对内存文件及逆行全局的爆破搜索很有效,但是也容易误判.
因为使用的方法(池标签扫描)依赖的数据敌手也可以伪造,所以你需要了解扫描技术到底怎么工作的、攻击者是如何避开这些扫描手段的,这也是本篇主要学习的内容。
此外,在得出结论之前,你应该习惯于结合多种证据来源来综合判断。