这篇复习&记录一下RabbitMQ。作为广泛使用的开源消息中间件的一种,RabbitMQ具有相较于kafka更丰富的消息推送模式(如自定义消息路由规则),此外,RabbitMQ也支持AMQP、MQTT、STOMP通用性开源消息协议以及如JMS的特定语言协议。
关于消息系统推荐一本国外著作:《Enterprise Integration Patterns : Designing, Building And Deploying Messaging Solutions》(《企业集成模式——设计、构建及部署消息传递解决方案》),书中以基于消息中间件的异步消息传递模型,给出了集成企业级应用的思路和模式(如书中定义使用命令消息和文档消息构建RPC给我留下了很深的印象)。

为什么要使用消息中间件?
这里我们讨论的背景放在微服务架构下、服务之间的通信。其实我个人理解消息中间件最大的作用——提供了一种不一样的异步通信的能力。
假设有两个微服务A和B,且服务均在线。其中A在业务流程中需要调用B的某个功能,或许这个功能耗时较长,我们选择了使用如FutureTask之类的方法,显式的让另一个线程去完成这个工作,A的主线程继续执行其他逻辑并在未来获取这个消息。
而如果采用了消息中间件呢?A只需要将这个调用的参数以消息(Message)的方式投递到某个实体中(在RabbitMQ中称之为Broker),并由B消费该消息、执行业务逻辑、最后将函数调用结果投递到另一个队列中。A在未来将从队列中消费这个结果以完成自己的业务逻辑。
在上述过程中,我理解所谓"不一样"的点在于,A不需要在代码中显式地向B发起HTTP请求,并阻塞等待B的响应结果。而是无所谓这个消息去到哪里这件事,我只要把message传递出去就好了,因为A知道这条消息总会被可靠地传递到B那里,并且自己将可靠地获取到B的消息。
上面这个例子其实本质上是一个基于消息组件的RPC例子。可以看出,A和B是一种松散、没有直接调用的关系,而满足这样关系的软件架构风格其实就是——事件驱动架构。
Messaging is a technology that enables high-speed, asynchronous, program-to-program communication with reliable delivery.
——《Enterprise Integration Patterns: Designing, Building, And Deploying Messaging Solutions》Gregor Hohpe & Bobby Woolf
那么事件驱动架构到底解决了什么问题?
以下内容参考自《分布式系统架构与开发》——郑天民 著
引入事件驱动架构的需求有两方面:
- 降低各个服务之间的耦合度
- 提升系统的可扩展性
而现有的REST、RPC架构在上述两个需求点上,各自存在如下问题:
对于耦合度
- RPC技术
- 技术耦合度:如Java的RMI等技术为语言特有技术,不同语言实现的服务之间无法消费。
- 空间耦合度:服务的消费者和提供者之间需要共享同意的方法签名才能协作(比如RMI,客户端需要和服务端本地都有待消费服务的接口定义)
- 时间耦合度:很好理解,双方都需要在线。
- REST技术
技术耦合度:只要支持HTTP就行空间耦合度:通过如HATEOAS在一定程度上实现接口的自解释- 时间耦合度:可惜,双方还是得在线
而如果使用如RabbitMQ这样的消息队列呢?
- 技术耦合度:Java、Python、C++、Go、PHP...几乎大部分常见的语言都有对应的Client API供你使用
- 空间耦合度:统一通过Client API消费消息队列中的消息。
- 时间耦合度:无所谓哪一方挂了,只要消息在队列且没有被确认,那么就可以可靠的在双方之间传递。
可以看到,消息队列能够满足系统改造时的耦合度需求。
可扩展性
当业务流程产生新的需求时,如何能在不影响原先业务的情况下,增加新的逻辑?
一个可行的方式就是增加消息中间件,将变化的部分投递到队列中,并由新增部分来处理,这样就避免了改变原先业务的逻辑,从而满足了业务可扩展性的需求。
简单使用
下面简单的介绍一下RabbitMQ中的基本概念以及给出一个整合基本使用方法的Demo
作为消息生产、消费的双方和中间存储、转发消息的消息中间件,首先具有如下三个基本的实体:
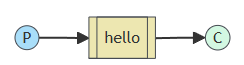
- 生产者(Producer):指生产消息并将消息投放到消息中间件的实体。
- 队列(Queue):具有接收、存储和发送消息功能的中间实体。
- 消费者(Consumer):指从消息队列中消费消息的实体。
当然,也可以多个消费者接到一个队列中,这就变成了一个单生产者-多消费者的模型,从而实现了对消息的并行处理。
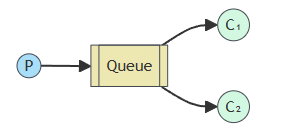
默认情况下,RabbitMQ会以RR的方式按顺序依次发送,如下图所示(三个消费者轮流消费消息):
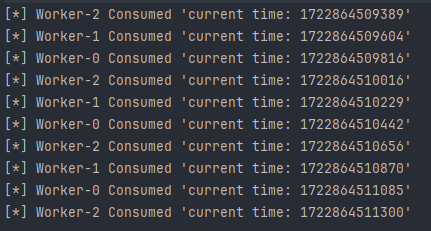
当然,也可以通过设置basicQos()参数为1,强制要求RabbitMQ未收到上一条消息的ack时,不发送下一条消息。
但是为了支持更多的消息传递模式(如直连、话题、头部、扇出),RabbitMQ中,生产者的消息一般发送给一个叫做Exchange的实体:
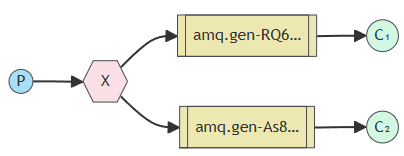
交换器的作用也很简单,甚至说有点类似交换机:
- 交换器(Exchange):从消息生产者处获取消息并以特定方式投递消息到消息队列中的中间实体。
The exchange must know exactly what to do with a message it receives. Should it be appended to a particular queue? Should it be appended to many queues? Or should it get discarded. The rules for that are defined by the exchange type.
通过定义交换器的类型,从而定义了交换器对消息传递的行为。至此我们就有了四个实体了。那如果我们有更多的队列,更多的消息类型,怎么定义更加丰富的消息传递方式呢?
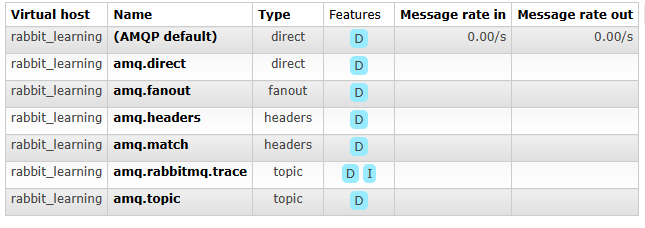
在RabbitMQ中,当我们新建一个virtual host以隔离,默认会有如下几个Exchange,各自代表了不声明交换器的情况下、默认的交换器名称,分别对应直连、扇出、头部、匹配、主题等。如何使用这些不同类型的交换器呢?
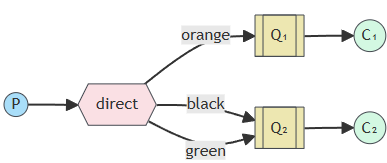
在交换器的基础上,RabbitMQ提供了路由键(routing key),从而将交换器中特定的消息和指定的队列进行绑定(Binding):
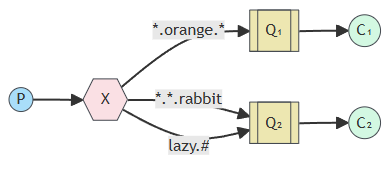
甚至通过"."连接的方式构造最长255字节的类似正则表达式的绑定规则:
结合上面的内容,这里给出一个小的Demo。在生产者部分,模拟一个生产者每隔1s投递一个指定类型的消息到Exchange中(app.*和error.*),并由Exchange按照对应绑定的路由键,将模拟的日志消息投递到不同的日志队列中。在消费者部分,模拟两个生产者,分别各自处理一种类型的日志:
1 | package routing; |
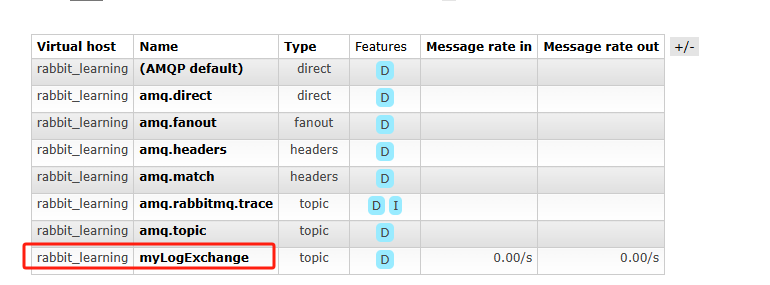
如上我定义了一个名为routing_demo的交换器,类型为直连,然后获取了两个不同的队列与其进行绑定,并在queueBind函数中传入了对应的routingKey名称。结果如下:
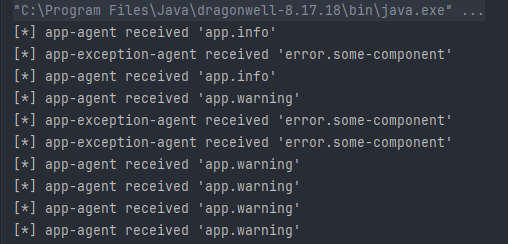
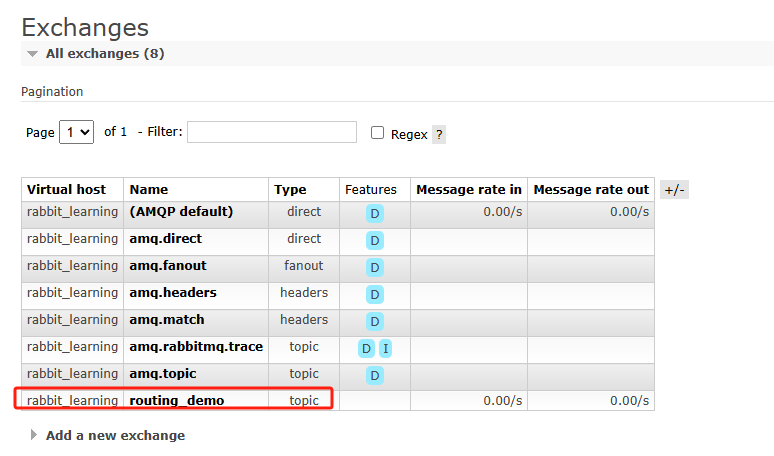
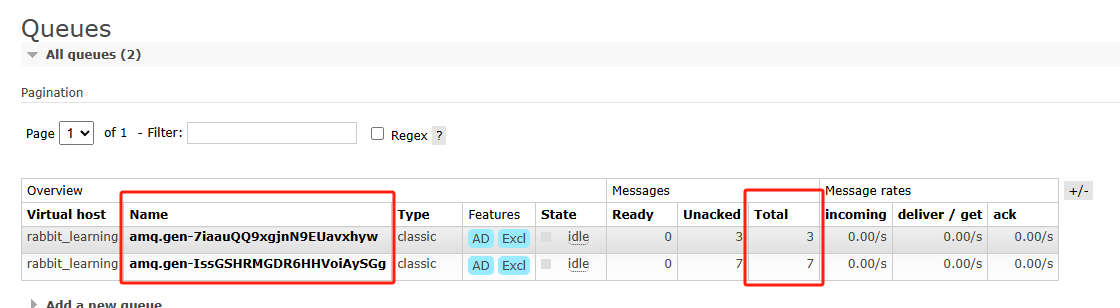
从web控制端面板查看,可以看到我们声明的交换器以及两个队列,且两个队列流经的消息总共10条。此外,所有app开头的消息都流入了路由键为app.*的队列中,而开头为error的消息则流入了路由建为error.*与上述结果一致:
RabbitMQ中的确认机制
既然要对消息做确认,那么就要考虑什么情况下会出现消息丢失?一个直接的思路就是,看看在一条消息从被生产出来,到中间件存储、转发,到被消费者消费这个过程中,三个实体各自会出现怎样的问题?——也就解释了为什么需要确认机制。
比如:
- 生产者应用所在机器网络发生了中断、生产者应用所在机器宕机了;
- 消费者应用所在机器网络发生了中断、消费者应用所在机器宕机了;
- 部署RabbitMQ的机器网络发生了终端、部署RabbitMQ的机器宕机了;
此外,还存在一些其他的因素如部分防火墙机制可能会断开空闲的TCP连接而导致网络中断、恶意程序导致的网络阻塞等
因此,为了解决上述问题,RabbitMQ中给出了acknowlegement和confirm机制,分别用于消费者通知broker该消息已经被接收且被正常的处理了和broker通知生产者该消息已经被消费者接收并合理的处理了。此外,在AMQP协议中也提供了心跳机制用以发现中断的连接,且避免了连接空闲而被中断。
具体而言,三个实体针对上述问题的应对方法如下:
在RabbitMQ中间件端
首先,为了避免自身机器出现宕机、需要服务重启从而导致队列、消息丢失的问题,RabbitMQ提供了持久化机制,因此,对于重要的消息,发布者在发布消息时应采用持久化的方式:
1 | Channel channel = connection.createChannel(); // 创建channel接口 |
这样即使RabbitMQ服务宕停了,恢复正常重启后仍然会保留我们创建的队列以及提交到了RabbitMQ中、尚未被消费的数据。
在生产者端
生产者端可能因为网络原因、宕机原因,导致了其与Broker的connection中断,在RabbitMQ中,此时生产者应重新发送broker没有收到Ack的消息。那么显然此时会在队列中造成消息重复的现象,因此这个问题就需要消费者那边对消息做去重了。
举一个例子来说明:
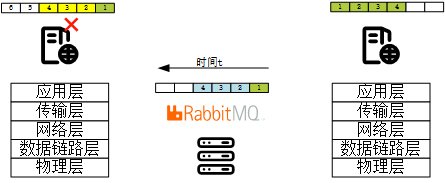
- 假设发送方发布了4条消息到队列中,并且接收方也从消息队列中消费了这四条消息,并向rabbitmq发送了confirm;
- 此时rabbitmq向发送方发送四条消息的acknowledge;
- 发送方接受到了第一条消息的acknowledge,但是此时发送方宕机了,导致后三条acknowledge没有收到;
- 那么在rabbitmq策略中,发送方恢复后,应当重新发送后三条没有收到acknowledge的消息;
那么显然这会导致队列中后三条消息出现重复,因此,rabbitmq要求消费者应当做好去重的工作:
There is a possibility of message duplication here, because the broker might have sent a confirmation that never reached the producer (due to network failures, etc). Therefore consumer applications will need to perform deduplication or handle incoming messages in an idempotent manner.
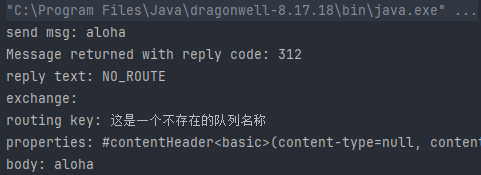
此外,考虑到生产者在发布消息后,想要知道自己的消息是否被正确的传递到了对应的队列中,RabbitMQ也提供了对应的参数以返回用于判断状态:

我们可以定义一个返回监听器并添加到channel中用以查看状态,如下代码演示了将一个消息投递到不存在的队列中,即投递失败了时候的结果:
1 | package basic; |
从结果中可以看到符合我们的预期,也由此,我们可以根据响应码来对不同情况进行处理:
在消费者端
在rabbitmq消息持久化、confirm-acknowledge双重确认的机制下,消费者端的宕机与否其实不会对消息的消费产生任何影响,只要恢复正常后就可以从rabbitmq中消费消息了。
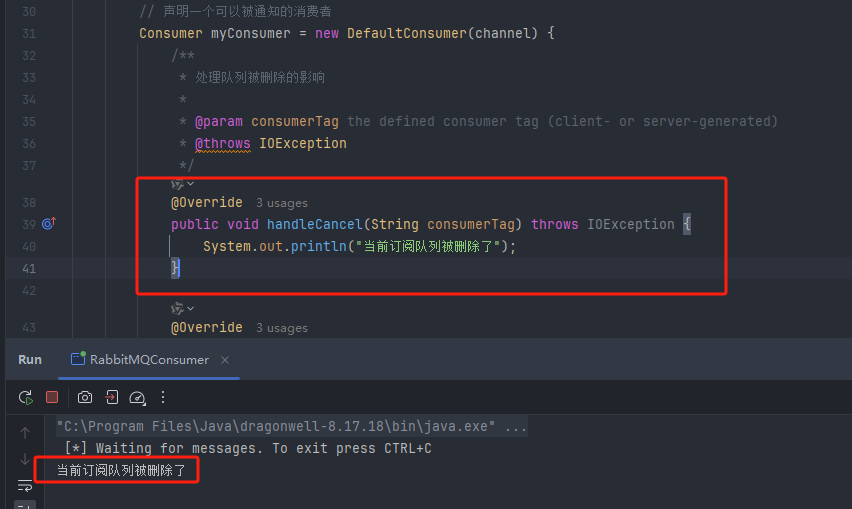
但有一种情况可能会影响消费者,那就是其消费的队列被删除了,此时消费者当然无法正常消费了。因此rabbitmq也提供了相应的机制:当一个队列被删除时,rabbitmq可以主动地、异步地通知消费者:
在Spring Cloud环境下整合RabbitMQ
相关版本如下:
| 组件 | 组件版本 |
|---|---|
| Spring Boot | 2.3.12.RELEASE |
| Spring Cloud | Hoxton.SR12 |
| Spring Cloud Stream | 3.0.13.RELEASE |
相关依赖项如下:
1 | <dependencies> |
从Spring Cloud 3.1开始,Spring Cloud Stream相关API已经大改,删除了@EnableBinding注解,改为了函数式的编程方法。因此以下内容仅限老版本。
Spring Cloud解决方案中,Spring Cloud Stream通过对消息发布和消费过程进行抽象,屏蔽了底层不同消息中间件的差异,提供了统一的使用方式。
Spring体系中,其实和事件驱动风格相关的组件或框架有四个,各自的用途和区别如下
- Spring Messaging:Spring Framework的一部分,提供了统一的消息编程模型。主要解决了如何在应用程序中集成AMQP(如RabbitMQ)、JMS(Java Message Service)等消息中间件的问题。
- Spring Integration:是对Spring Messaging的扩展,提供了一个基于消息传递的企业集成框架,支持了《企业集成模式:设计、构建及部署消息传递解决方案》书中的各种企业集成模式。适用于构建企业级集成应用,例如数据流处理、ETL(Extract, Transform, Load)任务、文件传输等。
- Spring Cloud Stream:专注于简化微服务之间的消息通信。提供了一种声明式的方式定义消息通道和绑定到消息中间件。适用于构建事件驱动的微服务架构,可以轻松地与不同的消息中间件(如RabbitMQ、Kafka等)集成。
- Spring Cloud Bus:主要用于在分布式系统中传播状态变化,比如配置更新、服务发现变更等。它利用了消息总线的概念,使得这些变更可以在集群中的所有实例之间传播。如动态刷新配置、服务发现通知等。
我个人理解为,Messaging是最基础的消息模块,而Integration在其基础上进行了模式的增强。而后面两个框架则是前两者在微服务架构下的实现。
对于Spring Cloud Stream,消息的生产者和消费者对应结构如下:
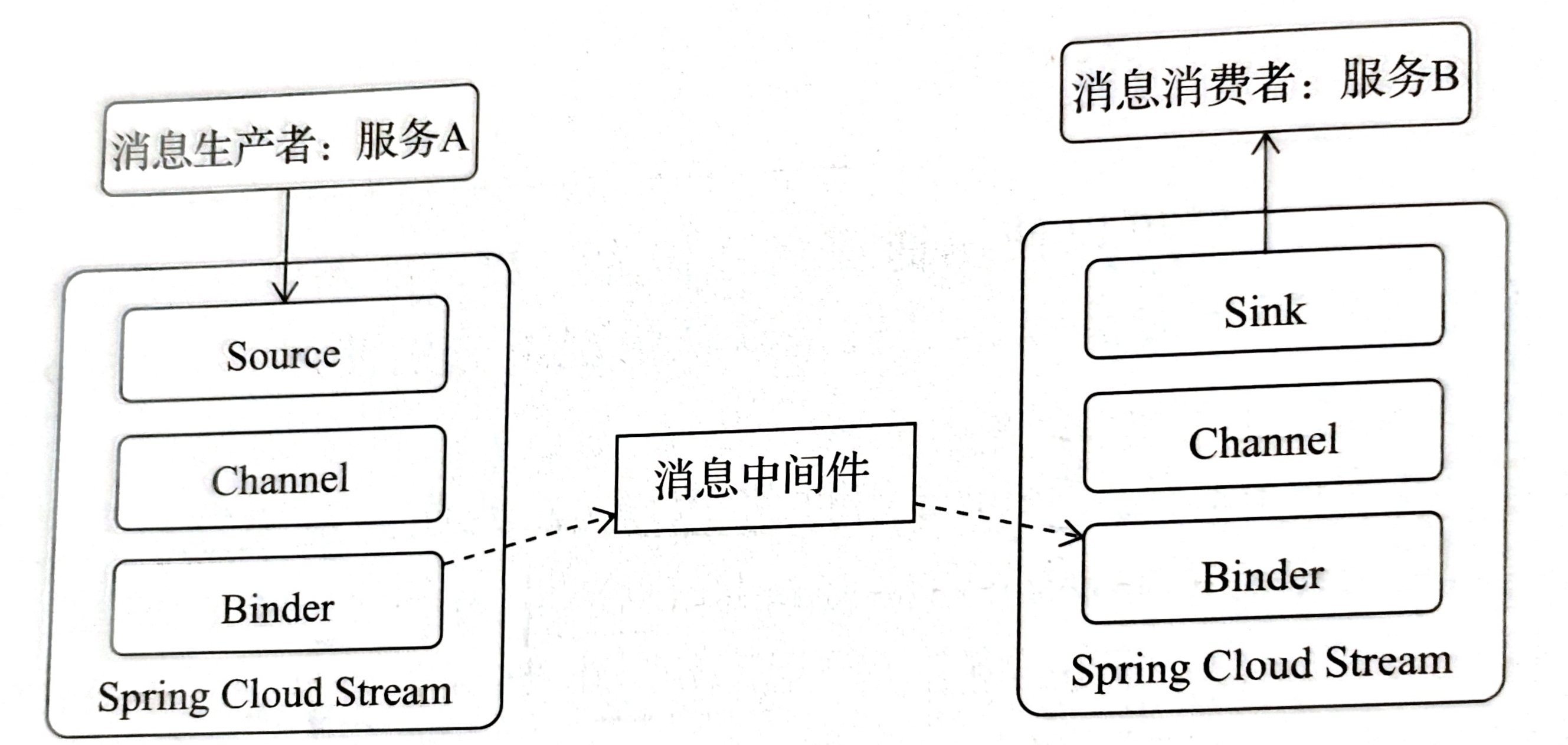
其中Channel对队列进行抽象,实现消息的存储和转发;Binder屏蔽下层具体中间件API,当我们更换底层中间件时,只需要更换对应的依赖Binder即可,如kafka使用spring-cloud-start-stream-kafka。
在Spring Cloud
Steam中,使用@Input、@Output、@Processor来定义生产、消费的通道,后者为前面二者的结合。我们可以定义如下队列:
1 | /** |
如上代码声明了一个名称为myLogOutputChannel的队列,此时,我们还需要在Spring配置文件中增加rabbitmq服务器配置和队列配置:
1 | spring: |
然后定义服务,并使用@EnableBinding注解向Spring
Cloud声明这是一个生产者应用,该注解会根据传入类(即声明的队列)中的输入、输出注解声明的队列名称创建对应的队列:
1 | /** |
对应的,我们可以声明消费者的队列。注意,这里单独声明了队列的名称变量是为了在消费者服务的@StreamListener中引用:
1 | /** |
定义消息消费者应用:
1 | /** |
结果如下:

在控制面板中也可以看到声明的交换器、队列: