
本篇复习一下Java中多线程编程技术,讨论如线程安全性和如何使用线程池的问题,并学习关于锁的相关编程方法。(ps:想我17年的i5-7200U只是个双核心四线程的,2022年换的笔记本都8c16了汗...AMD yyds嘿嘿

什么是线程?
进程我们都知道,一个进程中包含了要执行的指令、数据等等,通过使用多进程即可提高硬件的利用率。但是进程的创建、销毁需要消耗大量的系统资源。此外,多进程并行时变量的共享是一件很麻烦的事情。
因此,有了线程的概念。线程(Thread)是操作系统调度资源的最小单位,一个进程中可以包含多个线程,共享同一个进程空间中的变量。比如,当我们启动一个JVM进程时,可以通过JConsole观察到已经有一些线程在活动了,如垃圾回收线程、RMI线程等等。
一般的书中讲解声明周期的时候,都喜欢用5个状态来表示,如下5:
创建状态(New),可运行状态(Runnable),阻塞状态(Blocked),运行状态(Running),结束状态(Terminated)

- New:当使用关键字
new新建了一个Thread对象时,就处在该状态,此时并未执行,并未产生真正的线程,只是一个对象 - Runnable:当我们调用
start()的方法后,JVM中就会创建一个真正的线程,此时该线程就是可以执行的状态,等待调度器调度获取CPU时间片 - Running:当调度器选择了该线程时就可以运行了
- Blocked:如下情况会导致一个线程被阻塞挂起:
- 调用了sleep、wait方法,使得该线程加入了
waitSet - 进行了某个阻塞的IO调用,如网络读取数据
- 获得了某个锁资源,进入了该锁资源的阻塞队列
- 调用yield主动放弃了CPU执行权
- CPU调度器轮询使得该线程放弃了执行
- 调用了sleep、wait方法,使得该线程加入了
- Terminated:线程的最终状态,整个生命周期结束,可能的原因如下:
- 线程运行正常结束
- 线程运行出错意外结束
- JVM崩溃导致所有的线程都退出
实际在JDK的Thread类源码中,线程的状态定义如下:
1 | public enum State { |
共有六个,其中NEW、RUNNABLE、BLOCKED、TERMINATED与我们前述相同。没有RUNNING这个,而RUNNABLE其实已经暗含了RUNNING的意思了,即正在运行,但是有可能是在等待CPU时间片等资源。
Thread state for a runnable thread. A thread in the runnable state is executing in the Java virtual machine but it may be waiting for other resources from the operating system such as processor.
另外有WAITING和TIME_WAITING这两个状态。分别定义如下:
WAITING
Thread state for a waiting thread. A thread is in the waiting state due to calling one of the following methods:
- Object.wait with no timeout
- Thread.join with no timeout
- LockSupport.park
A thread in the waiting state is waiting for another thread to perform a particular action. For example, a thread that has called Object.wait() on an object is waiting for another thread to call Object.notify() or Object.notifyAll() on that object. A thread that has called Thread.join() is waiting for a specified thread to terminate.
TIME_WAITING
Thread state for a waiting thread with a specified waiting time. A thread is in the timed waiting state due to calling one of the following methods with a specified positive waiting time:
- Thread.sleep
- Object.wait with timeout
- Thread.join with timeout
- LockSupport.parkNanos
- LockSupport.parkUntil
因此如果我们用JDK中的状态来理解的话,应该是这样的:

如何使用线程
在Java中唯一创建线程对象的方法,就是使用new关键字创建Thread对象。具体的实现方式有两种:继承Thread类和实现Runnable接口。
继承Thread类
当一个类继承了Thread类后,需要覆写Thread的run方法,并通过new关键字即可构建一个可以运行的线程对象。这里的核心其实是模板设计方法。
看一个例子:
1 | package lzw.Thread.review.CreateThread; |
输出:
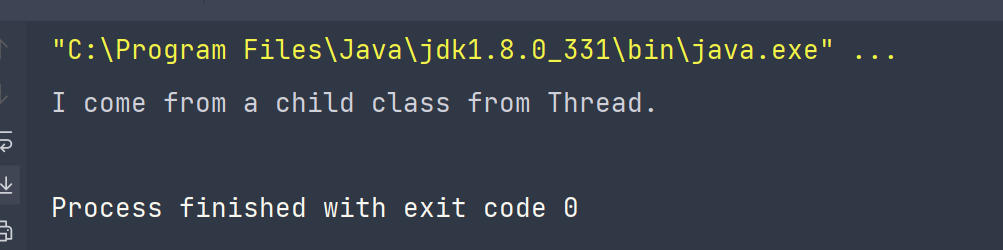
我们只需要继承Thread类并覆写他的run方法,并通过调用start()方法即可。这里重点关注一个问题,模板设计模式体现在了哪里?
模板设计方法:父类定义算法结构,子类实现逻辑细节
我们debug看一下:
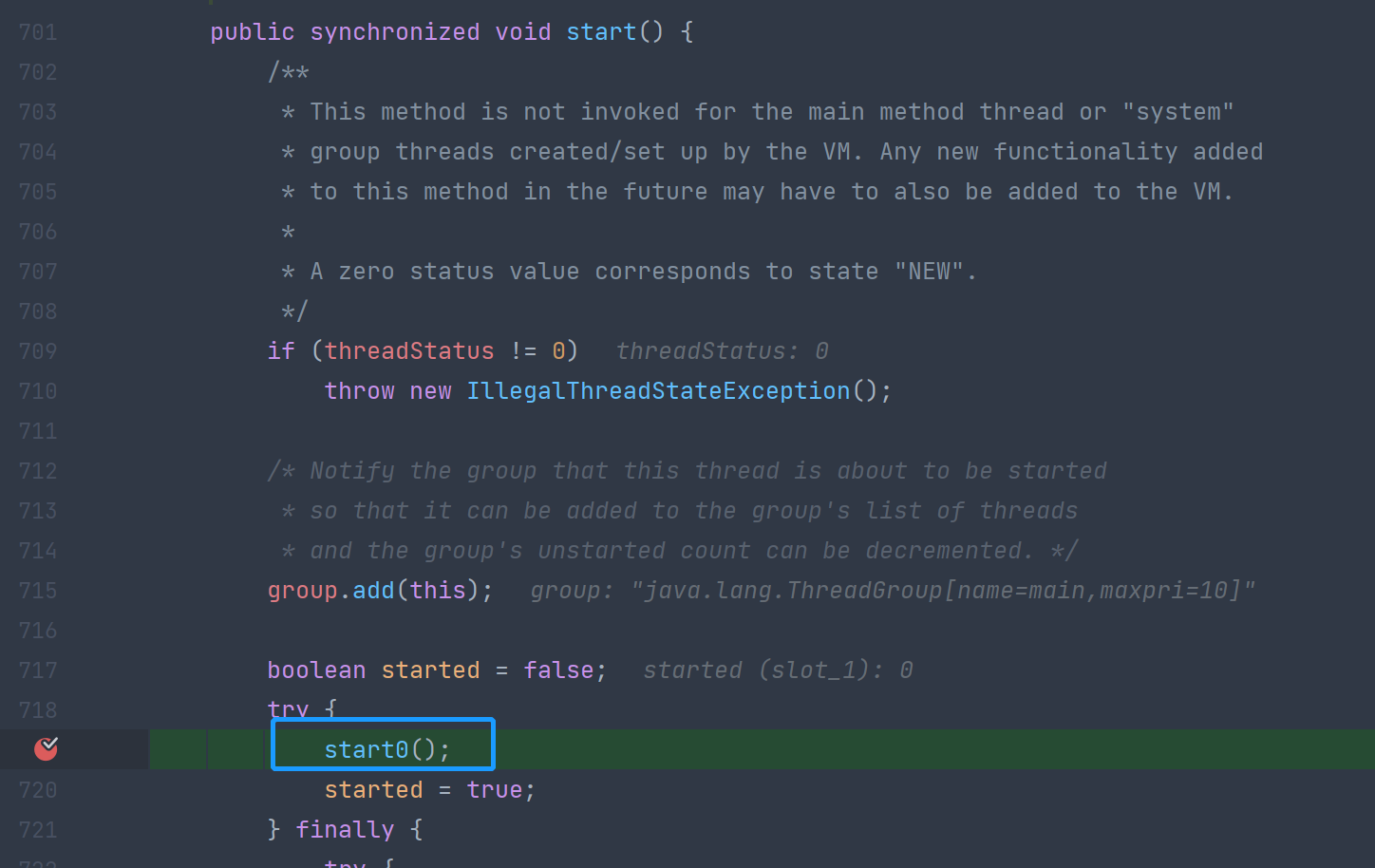
注意到这里实际调用的是start0()方法,继续跟进一下:

可以看到这是一个native方法,该方法的作用为使得JVM调用该线程的run方法。所以Thread.start()方法本质上会调用该线程的start0()方法,控制该线程启动。
模板在哪里呢?我们看一下Thread类原始的run()方法:
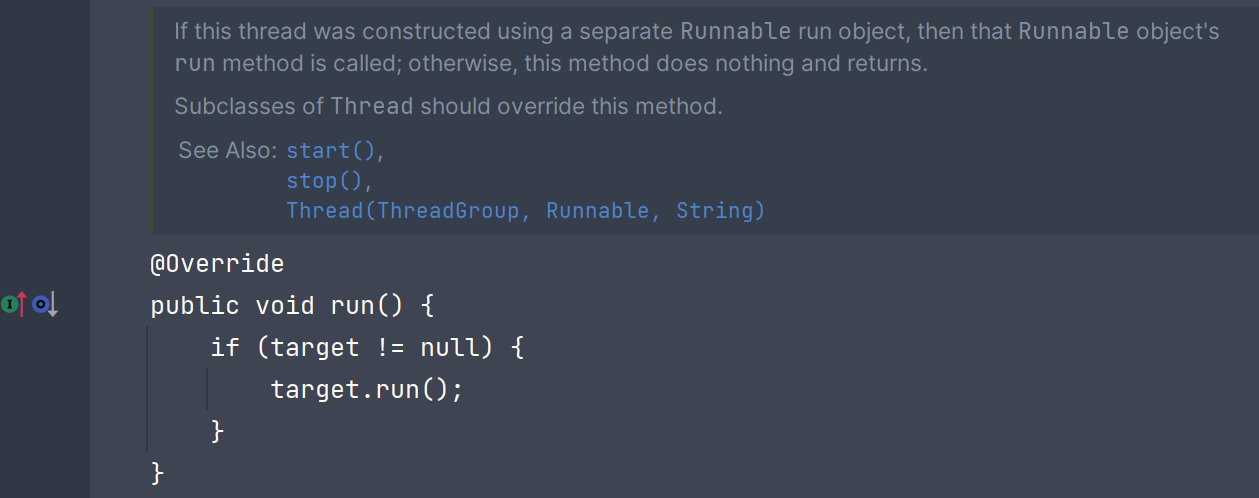
该方法是Runnable接口定义的,在Thread类中为调用target的run方法。而对于继承Thread类的写法,这个target是不存在的,即null:
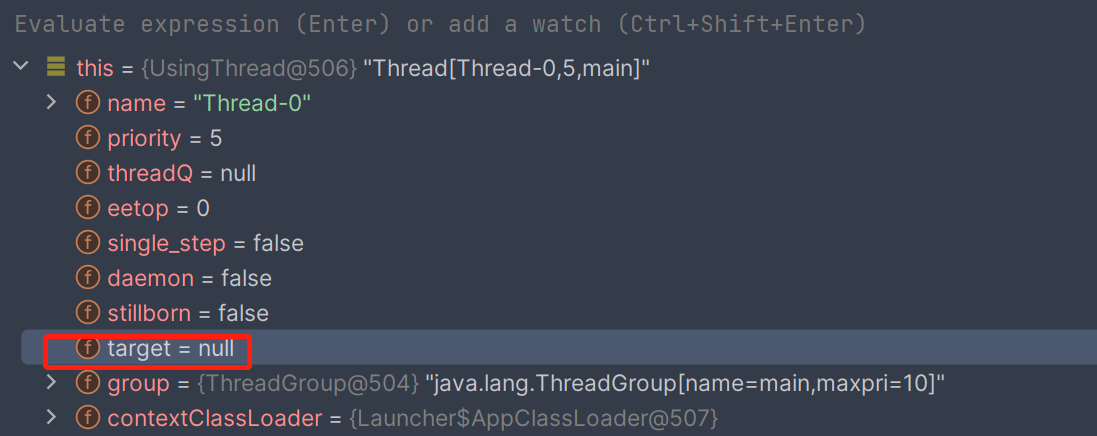
因此原始的Thread类中的run实际上是一个空方法。而start()函数会调用run()。这就是模板设计模式的体现了。
即子类(上述例子中的UsingThread)覆写父类(Thread)的逻辑细节(run方法),并由父类的算法逻辑调用具体细节(start方法)
实现Runnable接口
当一个类实现了该接口,并覆写了run方法后,即可以通过new关键字构造线程对象。代码如下:
1 | package lzw.Thread.review.CreateThread; |
运行结果:
debug看一下流程:

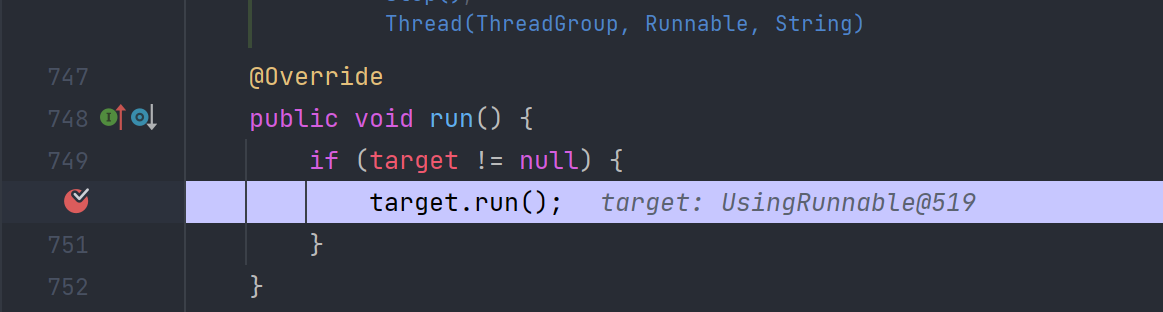
可以看到仍然是要调用start0方法,只是此时,taget变量已经有指向了,即我们定义的实现了Runnable接口的对象。自然而然,start0方法也就使得我们进入了上述方法:
区别
继承Thread类的方式,不同线程不能共享同一个run执行单元,即各自运行各自的run方法;而Runnable方式,不同线程可以共享同一个run方法单元:
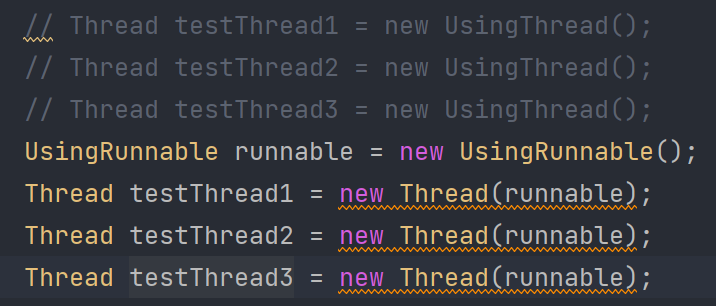
啥意思呢?如果你是继承Thread的方式,不同线程想操纵同一个类内变量的话,那就得把它声明为静态变量了。
而继承Runnable接口的方式由于只存在这一个类实例,因此天然的大家可以操作同一个类内变量。
常见线程API
sleep
字如其意,让当前线程休眠,暂停执行。方法声明如下:
2
public static void sleep(long millis, int nanos) throws InterruptedException
其中,第二个精度更精细,可以在睡眠毫秒数后,再睡眠纳秒。使用方法也很简单:
1 | package lzw.Thread.review.basics; |
当然使用JDK 1.5后提供的sleep的封装,TimeUnit类的话可读性会更强:
1 | package lzw.Thread.review.basics; |
这部分唯一一个注意的地方就是,sleep函数的调用不会使得当前线程释放已经持有的锁:

yield
这个方法比较少用,作用是暂时放弃当前的CPU资源。但是如果CPU资源充足的话,会忽略这个放弃请求。给一个例子:
1 | package lzw.Thread.review.basics; |
我们创建了两个线程并调用start方法,其中第二个线程若优先得到CPU资源,则会yield让出给第一个线程,由RUNNING状态转变为RUNNABLE状态。此时理论上输出应该始终是0, 1。但是前面也提到了,CPU资源充足时候,会忽略。
join
方法声明如下:
2
3
public final synchronized void join(long millis) throws InterruptedException;
public final synchronized void join(long millis, int nanos) throws InterruptedException
第一个本质上调用的是join(0),第三个就是多了纳秒而已。主要看第二个。给一个例子:
1 | package lzw.Thread.review.basics; |
下面是输出结果:
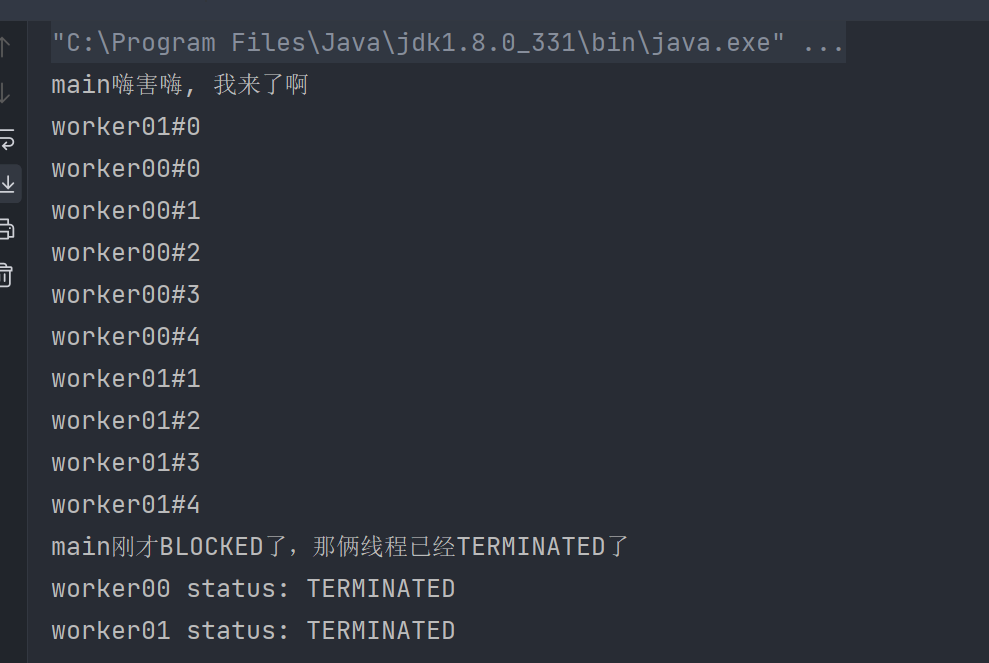
可以看到,主线程调用worker01、worker02线程的join方法后,会从RUNNING状态变为BLOCKED状态,直到join对象的线程生命周期结束。中间可以看到二者轮流输出,这是抢占式CPU调度的结果,当他们都运行结束后,即TERMINATED后,主线程才会继续自己的工作。
interrupt
划重点,这个API很重要,函数声明如下:
该函数用于打断一个线程的阻塞状态。哪些函数会使得线程进入BLOCKED状态呢?如下:
- Object.wait()、Object.wait(long)、Object.wait(long, int)
- Thread.sleep()、Thread.sleep(long)、Thread.sleep(long, int)
- Thread.join()、Thread.join(long)、Thread.join(long, int)
- InterruptibleChannel的io操作
- Selector的wakeup方法
而interrupt方法会打断上述线程的阻塞状态,因此上述方法也叫“可中断方法”。当一个线程在运行时,若执行中断操作,则会抛出InterruptedException异常,给一个例子。此外,我需要重点说明一下interrupted标识符。
1 | package lzw.Thread.review.basics; |
我们创建一个线程,他的执行逻辑是睡眠1分钟,而sleep方法是一个可中断方法,因此当我们手动中断后,会进入catch代码块:

这里我们重点看一下interrupted标识符,他是线程对象内的一个变量,用于表示该线程是否被中断。而线程也会不断的去检查这个标识符:

若当前线程被中断,则该位设置为true。但有一个特殊的点,即,若该线程执行的方法为可中断方法,则在中断后,会自动清除该标志位。如下:
1 | package lzw.Thread.review.basics; |
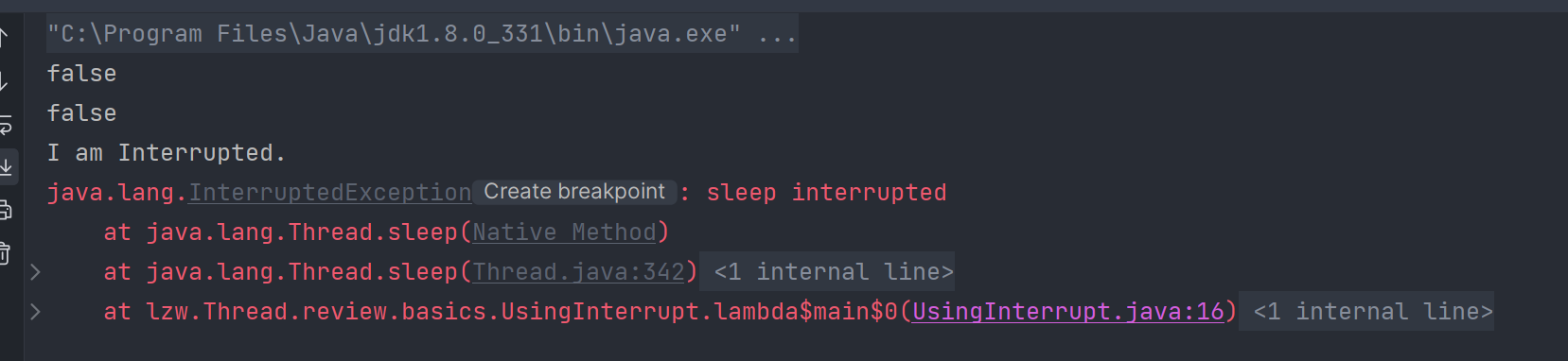
可以看到,两次输出都是false。而若非中断方法,比如我们只是单纯的循环:
1 | package lzw.Thread.review.basics; |
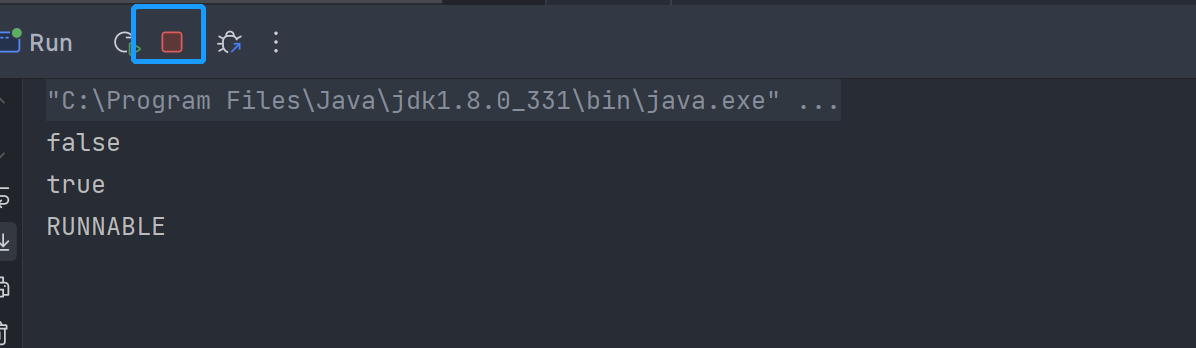
则可以看到第二次输出为true,且当前程序并未结束,说明被中断的线程并非结束了自己的声明周期,上图中就显示为RUNNABLE而非TERMINATED。
此外,在Thread类中还有一个与这个方法很像的****:interrupted,该方法作用相同,但是会擦除flag标识位,如图:
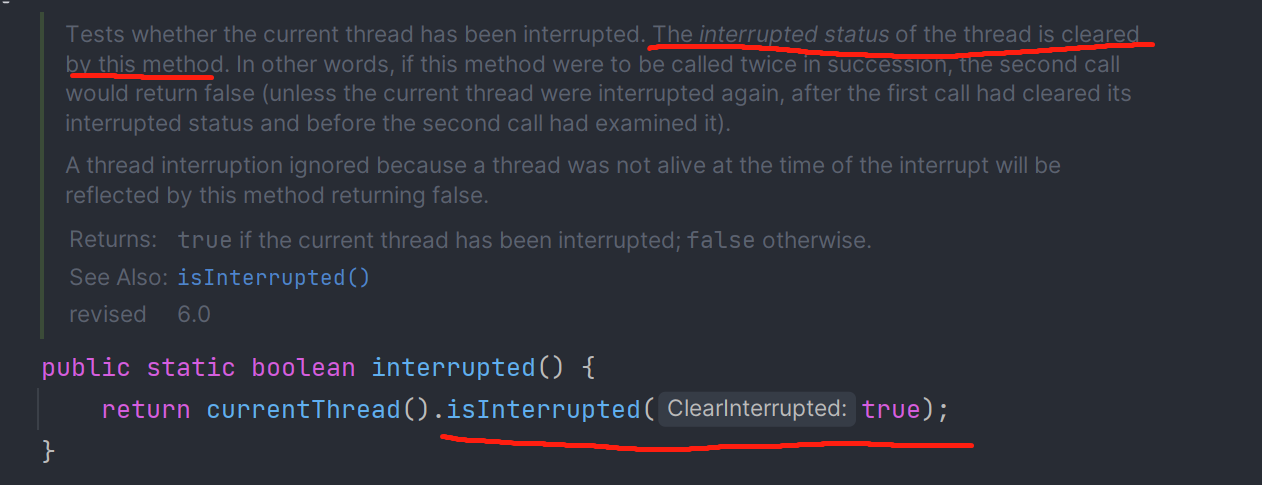
获取线程信息(线程对象、ID、上下文类加载器)
- 线程对象
- ID
创建线程的ID从0开始,依次递增1。
- 上下文类加载器
可以得知这个线程是由哪个类加载器加载的。如果没有修改上下文加载器的话,默认为父线程的类加载器。
经典生产者-消费者问题--线程间如何通信?
单线程间通信
我们先分别定义生产者和消费者,其中生产者生产对象时不需要时间,而消费者需要时间来消费一个对象。
- 首先我们定义一个用于定义生产和消费的对象,并定义一个服务
TransactionService,该服务中维护了一个单例的链表。 - 然后分别定义生产者和消费者代码
- 定义两个单线程分别执行生产和消费
具体代码如下:
1 | package lzw.Thread.review.entity; |
1 | package lzw.Thread.review.demo; |
1 | package lzw.Thread.review.demo; |
1 | package lzw.Thread.review.demo; |
这里核心的部分就是sychronized代码块,以及wait和notify操作。
首先需要明确的是,wait和notify操作必须在同步代码块内才可以使用。进入同步代码块后,首先我们会块持有的,是单例对象的Monitor。对于消费者而言,若队列为空,则加入该Monitor的等待集合中;对于生产者而言,如队列已满,则加入该Monitor的等待集合中。上述操作是通过wait函数完成的,此时将释放所持有的Monitor对象。
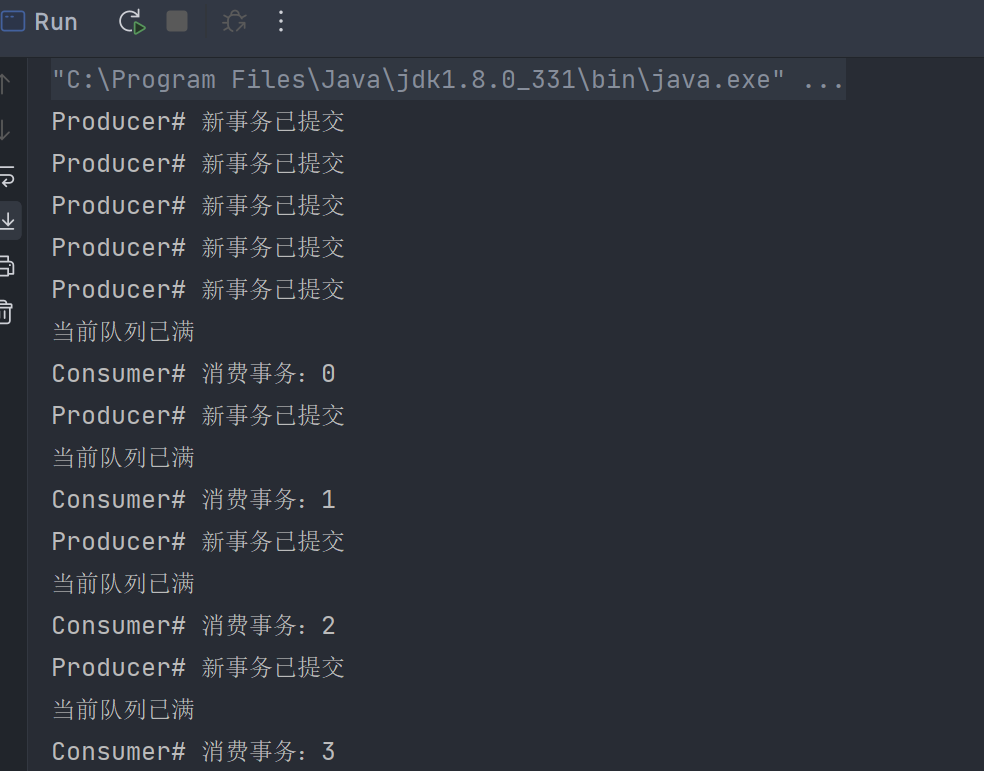
而当生产者新生产了数据以及消费者消费了数据之后,将会调用Notify方法,唤醒该Monitor等待集合中的线程。部分运行结果如下图:
多线程间通信
上面我们使用Wait和Notify函数完成了两个单线程之间的同步,实际上,多线程之间也有类似的机制。
我们仍使用上述的Producer和Consumer,只需要将notify函数更换为notifyAll即可。运行结果如下:
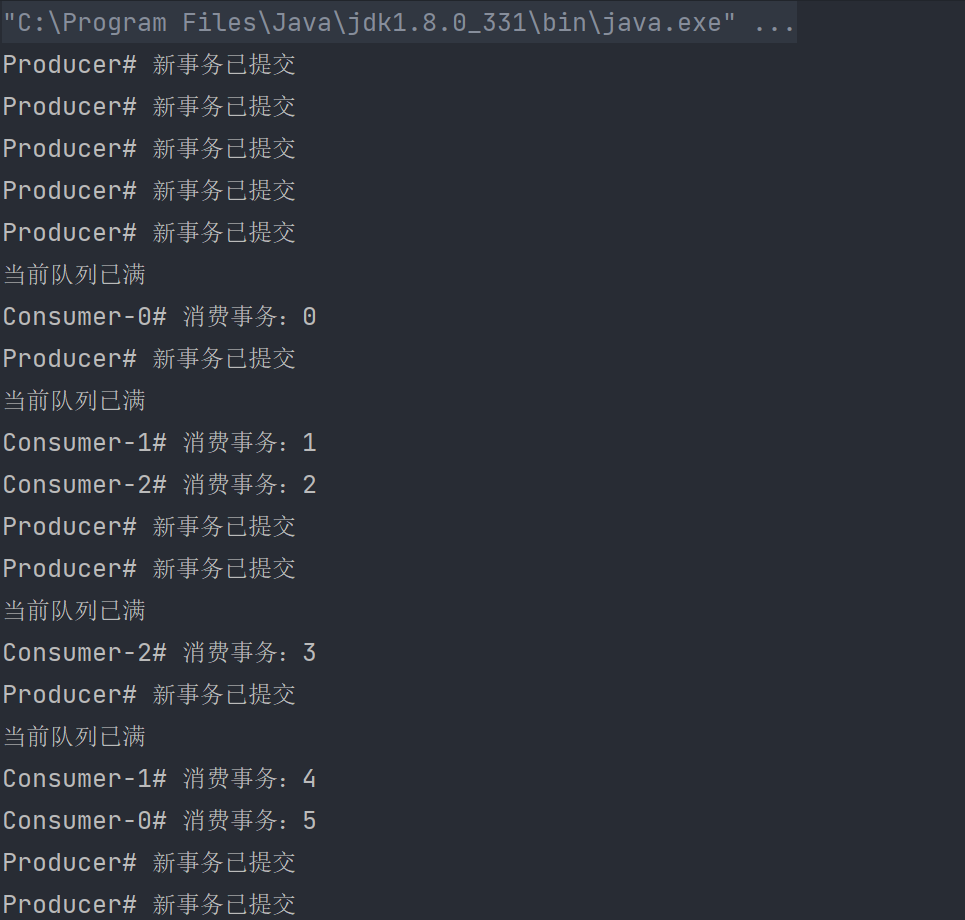
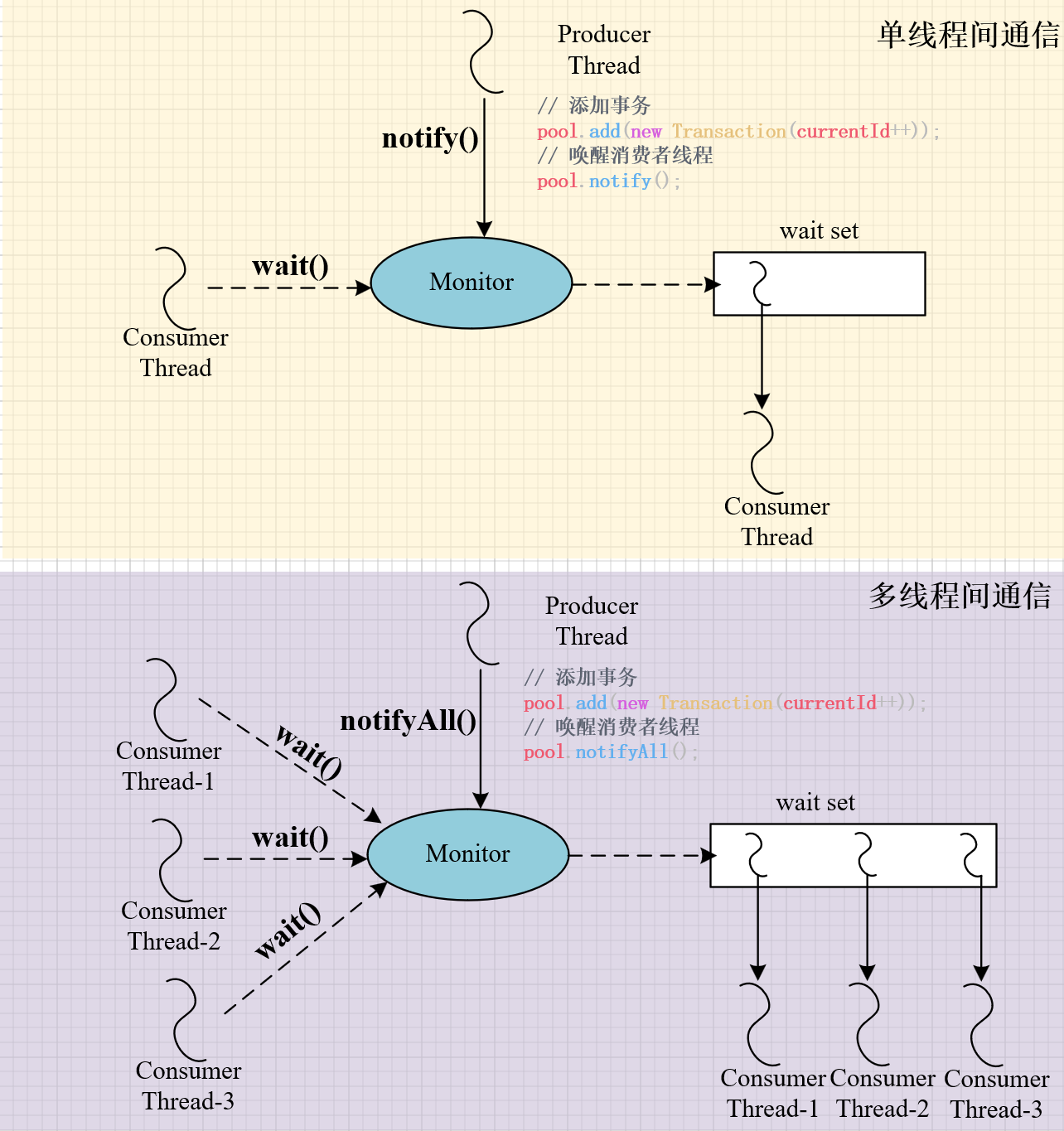
wait和notify、notifyAll时发生了什么
深入浅出的说明一下。这三个函数首先需要在同步代码块中使用,即前提是,持有了Monitor,否则会抛出IllegalMonitorStateException异常。而每一个Monitor都对应拥有一个线程休息室(wait
set),具体实现与JDK实现有关,我们以oracle的JDK为例。其中,单线程和多线程通信的过程如图所示:
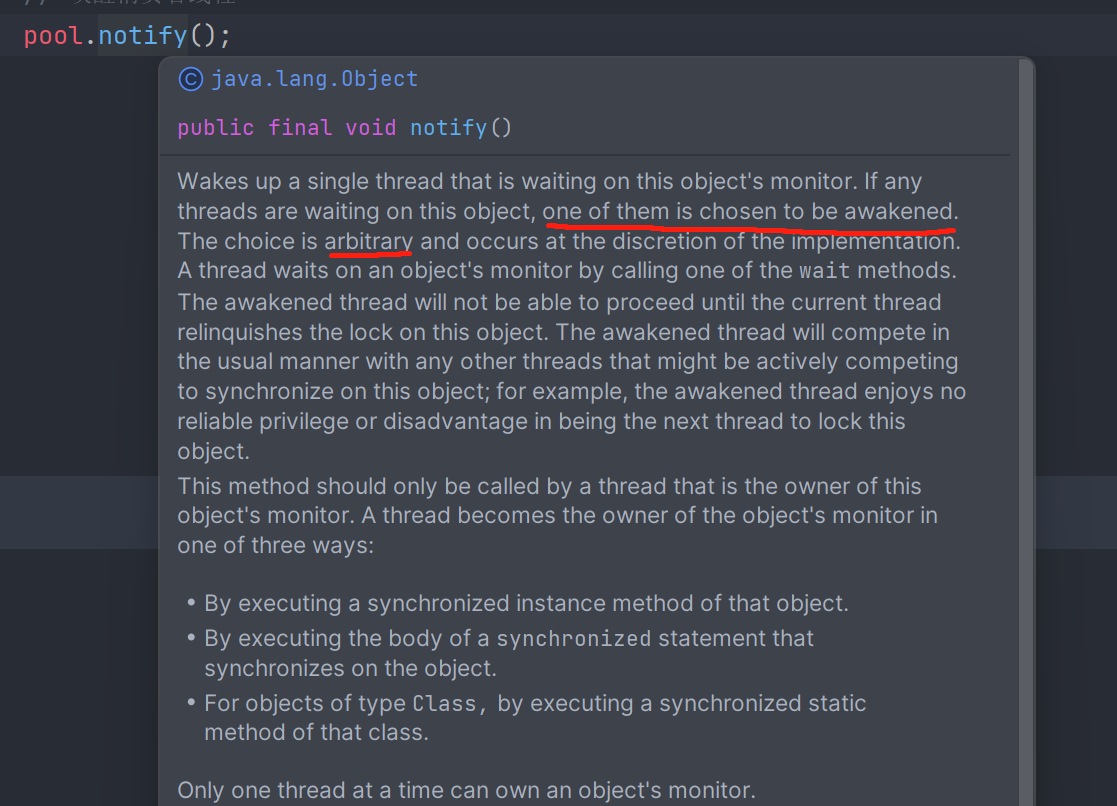
而若是多线程下,我们使用notify()函数而非notifyAll(),则会导致不同步的问题。在oracle JDK的实现中,notify会随机唤醒一个线程:
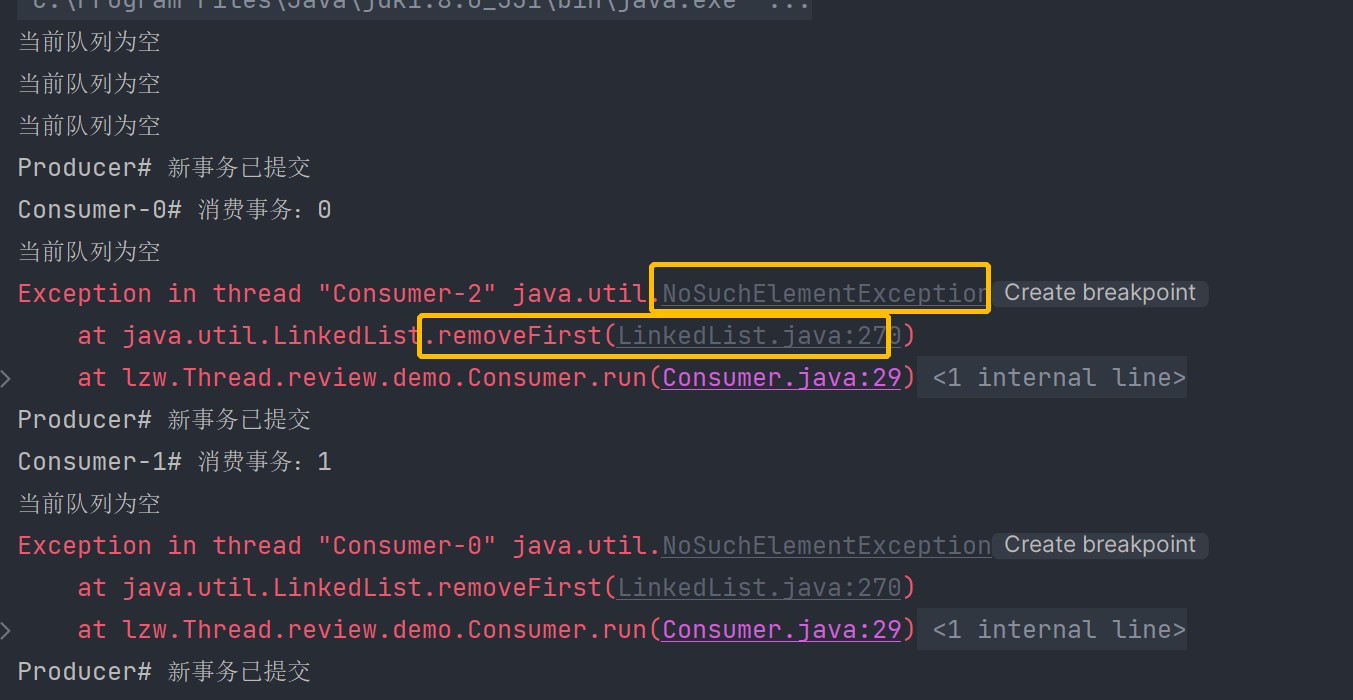
举一个简单的例子,假设我们有两个消费者线程,当前队列为空。当生产者放入一个对象后,notify方法会随机的唤醒一个消费者线程。此时,该消费者线程在取出对象后,会再次调用notify方法,而此时唤醒的是另一个消费者线程,直接进入了消费代码片段,就会导致从空列表中获取数据的操作。如图:
使用线程池
由于线程的创建、启动、销毁都比较耗费系统资源,因此有了线程池。线程池中的线程可以重复利用,提高系统效率。JDK
1.5开始提供了Executor和ExecutorService接口以及对应的一系列实现。一个线程池具有如下关键要素:
- 任务队列:用于缓存我们提交的Runnable的任务
- 线程数量管理:关键数量包括:初始化线程数量init、自动扩充时的最大阈值数量max、维护核心线程数量core。关系为init<=core<=max
- 线程工厂:用于创建线程
其中Executor接口定义如下:
1 | public interface Executor { |
而ExecutorService接口则在上述接口的基础上,提供了更多用于任务提交和管理的方法:
重点学习该接口的两个实现:ThreadPoolExecutor和ScheduledThreadPoolExecutor。